
統計学における重要な概念である「信頼区間」に焦点を当てています。母集団の特性を推測するために標本データを使用する際に生じる不確実性に対処する手段として、信頼区間がどのように計算され、解釈されるかを詳しく解説しています。また医療統計の視点からもアプローチし、信頼区間がP値と比べて提供する情報の豊富さについて考察しています。
信頼区間とは
推測統計の目的の一つとして、母集団の特性を推測することが挙げられます。
代表的な母集団の特性の一例として、 母平均(つまり母集団におけるある変数の平均値)があります。
例えば、この母平均を正確に求めるためには、実際に母集団内のすべてのデータを収集する必要があります。
もし、母集団がある程度の有限数ならば可能ですが…、
ほとんどの場合は母集団は無限もしくは有限でもデータを収集して回るには、費用と時間がかかりすぎて現実的ではありません。

その代わりに、通常、母集団全体から無作為に標本を取り、その標本データを使って母集団の特徴(上の例なら「母平均」)を推測します。
例えば、お住まいの周辺地域の高齢者(例えば70~75歳)の平均握力や平均歩行時間が、どの程度なのかを推測するために、周辺地域の全70~75歳の体力測定データを集める代わりに、無作為に標本抽出し、この標本の平均握力や平均歩行時間を使って真の母集団の平均を推定することができます。

この時、問題となるのは、
標本として抽出された方々が母集団(周辺地域の70~75歳以上の方)と完全に一致することは無いのでは?
という懸念ですね。
「もしかしたら、偶然に体力低下傾向の偏った標本やその反対を抽出するのでは?」
この懸念(不確実性)を保証する為に、信頼性のある確率で母集団を含むであろう範囲を計算で求めたのが「信頼区間」です。つまり、信頼区間とは
標本平均 ± (臨界値) × (標準誤差)
で、表されます。
この計算式により、信頼区間は、上限と下限のある区間の中に、母集団のパラメータ(例えば母平均)をある確率で含んでいる範囲ということになります。
信頼区間は一般に
[下限値、上限値]
で表示されます。
医療統計における信頼区間の重要性
医療統計では集めた標本データーを使ってリサーチクエッションに対する答えを導き出すことを目的としたものですね。
そして、このリサーチクエッションに対する答えの根拠としてP値が頻繁に使用されます。過去20〜30年間で医療統計分野は飛躍的に増加してきた一方で、仮説検定に過度に重点を置くようになったという事実があります。データは統計的な "帰無仮説 "との関連で検討され、研究者は "統計的有意性 "を得ることを目指すべきであるという誤った考え方も蔓延しました。
しかし最近では研究者の中には、
「信頼区間はデータからP値よりも多くの情報を与えてくれる」
と考える方々も少なくありません。
この信頼区間は推定された統計量に関する誤差情報、言い換えれば、母集団から標本を採取した際に生じる”バラつき”を反映した範囲だといえます。また信頼区間は、未知のパラメータが信頼区間に入るという「信頼度」を反映しているともいえます。
信頼区間の正しい解釈
信頼区間を求める際には、
① 区間に含まれる値
② 区間の範囲
に注目して解釈することが重要となります。
区間に含まれる値
信頼区間は一般的には「95%」で求めます。例えば95%信頼区間と言えば、
「求められた区間に95%の確率で母集団のパラメーターが入る」
と解釈していませんか?答えは”ブー”です。

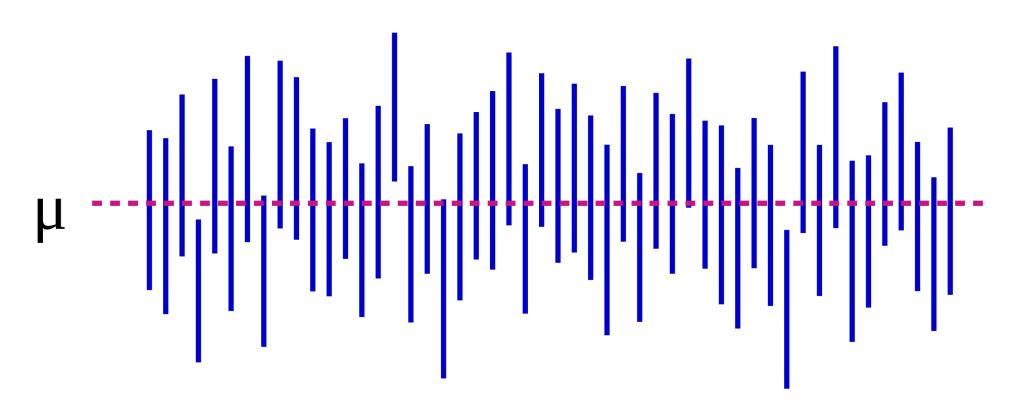
信頼区間では、どこかに存在している真の母集団パラメーターが95%の割合で「含まれる」区間を表しているので、
「母集団から標本を抽出して信頼区間を求めることを反復したら、100回中95回の割合で信頼区間は母集団のパラメーターを含んでいる」
という解釈が正しい解釈となります。
ちなみに95%の確率ではなく、”割合”となっていることにも注意して下さい。
信頼区間に真の値が存在する確率は「含まれる=100%」か「含まれない=0%」です。
実際にはデータ収集は1度しか行っていないので、「100回中95回の割合で真の値が含まれる」といわれても腑に落ちない感覚が残りますね😓。
下の図は信頼区間を50回反復した例ですので、参考にしてみてください。
区間の範囲
信頼区間は「あるパラメータ(例えば平均値)がどれくらいの範囲にあるかを推定するための区間」であると考えると、その区間の範囲にも注目が必要ですね。
例えばあるデータの平均値が、母集団の平均とどれくらい異なるかを知りたい場合、
「信頼区間が狭ければ狭いほど、推定された平均値がその周りに集中している」
という解釈ができます。一方、
「信頼区間が広ければ広いほど、推定された平均値がバラつきがある」
という解釈ができます。
つまり、信頼区間の広さや狭さを見て、「この推定はどれくらい確かだろう?」と考え、信頼区間の範囲が小さいほど、その推定がより精密で信頼度が高いと考えることができます。
母平均の信頼区間
母平均の信頼区間を計算する場合の信頼区間の公式は次のようになります。
信頼区間 = 標本平均 ± z ×(s/\(\sqrt{n}\))
ここで
- z: 選択された z 値
- s: 標本の標準偏差
- n: 標本サイズ
です。また使用するZ値は、選択した信頼水準に依存します。
一般的な信頼レベルとしては95%が使用されますので、Z=1.96です。
例えば、ランダムに選んだ周辺地域在住70~75歳の女性の握力が
- 標本平均:23.25㎏
- 標準偏差:11.81㎏
- 標本サイズ:30人
- z:95%
なら、95%の信頼区間は
23.25±1.96×(11.81/\(\sqrt{30}\))=23.25±4.23
[19.02, 27.48]
となりました。
信頼区間での帰無仮説の解釈
さらに信頼区間と仮説検定は密接に関連していることも理解しておきましょう。
もし差の95%信頼区間がゼロを含む場合、
「P値は0.05より大きい」
という解釈になります。
具体例を使って考えると、男女の各100人の身長差の推定値が、平均身長差(男性-女性)は5.0cmで、95%信頼区間は1.78cm~4.56cmであったと仮定します。
この信頼区間は正の範囲内であるため、「このサンプルの男性は平均して女性より1.78cm~4.56cm、背が高い」こと意味していますね。仮説検定(帰無仮説)的に表現すれば、「男女の平均身長は同じではない(=0ではない)」ということになります。なぜなら、95%信頼区間である1.78cm~4.56cmはゼロを含んでいません。
しかし、この信頼区間が、-1.78cm~4.56cmであった場合、女性は男性より1.78cmまで背が高い(負の差)可能性があるし、男性は女性より4.56cmまで背が高い(正の差)可能性があるかもしれないですね。さらに信頼区間がゼロを含んでいるので、「男女の身長は同じかもしれない」という解釈も可能になります。なぜなら、男女の平均身長が同じである”ゼロ”可能性を排除することはできないからです。この場合を仮説検定(帰無仮説)的に表現すれば、「男女の平均身長は同じではない(=0ではない)」を棄却できなくなります。
※注意点として、信頼区間をP値と同様にイエスかノーかの答えを出すものだと捉えてしまわないようにして下さい!なぜなら臨床的な結果の重要性を考えることも含め、信頼区間に含まれる重要な情報を見落としてしまうことになりますので、前述した「信頼区間の正しい解釈」を基本に考えていきましょう。
医療統計の分野ではヒトの健康に関する研究ですから、研究者の関心は、例えば、グループ間の母集団における結果の差の大きさを決定することであり、それらが異なるかどうかの単純な表示ではないですね。
信頼区間は、標本データを使って導き出される値の範囲から抽出され、標本が属している母集団における未知の値に関する妥当な範囲を教えてくれるものです。つまり信頼区間の意味を理解することは、自らの研究を報告する上でも、批判的な目で文献を読む上でも、非常に有用であると考えられます。これを踏まえて、British Medical Journalに掲載される論文(およびその他の論文)には信頼区間を推奨しています。
信頼区間を締めくくる前の注意点
信頼区間の大きさに影響を与える要素として、
1.標本サイズ:
標本サイズが大きければ大きいほど、信頼区間は狭くなります。
2.信頼水準:
信頼水準が大きいほど、信頼区間は広くなります。
例えば、信頼レベルとしては99%ならば、Z=2.58と大きくなっています。
まとめ

信頼区間についてまとめてみました。研究などの統計解析でも信頼区間をしっかりと検討しなければいけない場面も多くあると思いますので、基本的な理論を理解しておくことは大事ですね。


コメント