例えば、日々の臨床の中で、次のような疑問を一度は考えたと思います。
現在、担当している患者(82歳男性)の体力は、一般的な同年代と比べてどの程度低下しているのか?
高齢者の血圧や血糖値の平均はどのくらい?
脳血管障害後の下肢筋力はどの程度あればADLは自立するのか?
これらは、それぞれにある”母集団”についての疑問を考えています。
1番目の疑問の母集団は「日本中の82歳男性」、2番目ならば「65歳以上の日本人全員」、3番目ならば「脳血管障害患者」となりますね。
つまり母集団とは、対象となるすべての要素を含む集団全体を指します。
しかし、母集団内のすべての要素をデータとして収集するのは不可能です(記事後半に説明しています)。
その代わりに、統計学では母集団の一部を標本データとして収集します。
- 母集団:測定対象であるすべての個人要素
- 標本:母集団の一部からランダムに抽出された要素
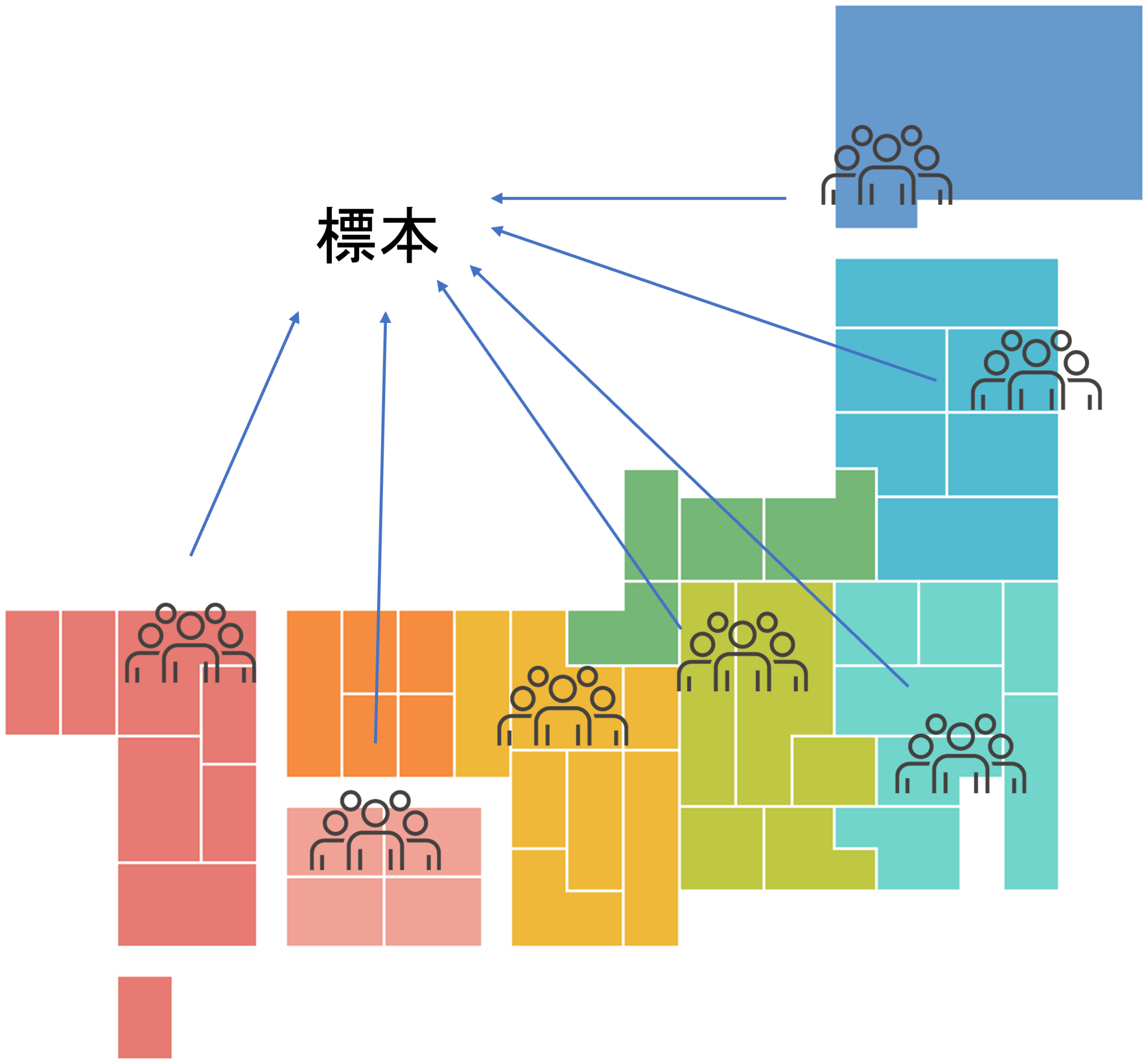
例えば上記の最初の例の「現在担当している患者(82歳男性)の体力は、一般的な同年代と比べてどの程度低下しているのか?」なら、
母集団全体は日本中の82歳男性となりますが、標本としては、下の図のように「日本各地方から抽出した82歳男性の体力データ」が一例として考えられます。
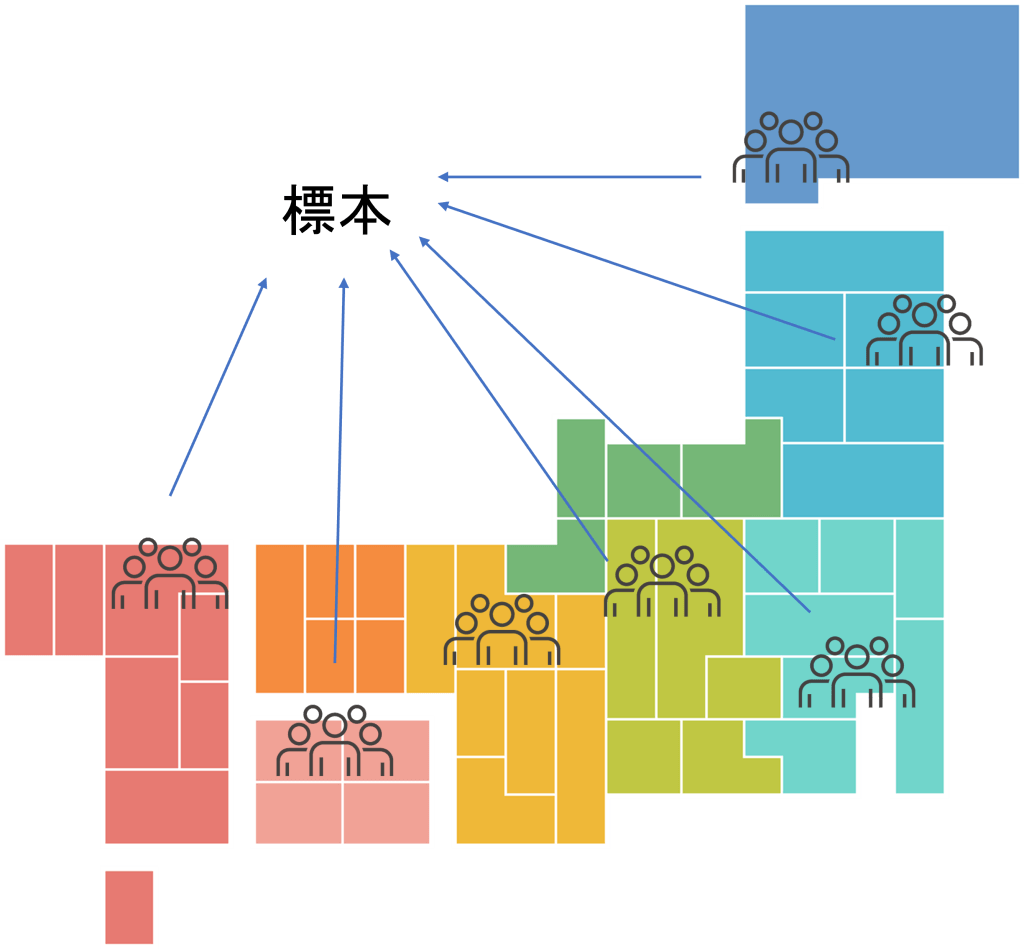
なぜ標本?
統計学ではほとんど場合において、母集団データを扱うのではなく、標本を基にデータ解析を実施します。
それには、以下のような理由があります。
- 母集団全体のデータを収集するには膨大な時間を要する。
- 例えば、日本中の82歳男性の体力を測定するに、すべての82歳の家を訪問して体力データを収集しても数年かかるかもしれません。そんなことをしている間に、対象となる母集団は変化してしまったり、そもそも調査の目的自体に意味が無くなっているかもしれません。
- 母集団全体のデータを収集するのはコストがかかりすぎる。
- 母集団に属するすべての人のデータを収集するのはコストがかかりすぎます。何人のスタッフを集めれば短時間に82歳男性の体力評価ができるのか見当もつきませんね。
- 母集団全体のデータを収集することは不可能である。
- 多くの場合、母集団内のすべての人のデータを収集することは不可能です。
一方で、標本データ収集であれば、対象となる母集団の大まかな情報をより早く、より低予算で集めることができるのです。
また、標本が母集団を代表するものであれば、標本から得られたデータから信頼性の高い母集団についての一般化した情報を得ることができます。
標本抽出の重要性
母集団から標本データを集めるとき、重要なのが、その標本が母集団の「縮小版」であることが理想的です。
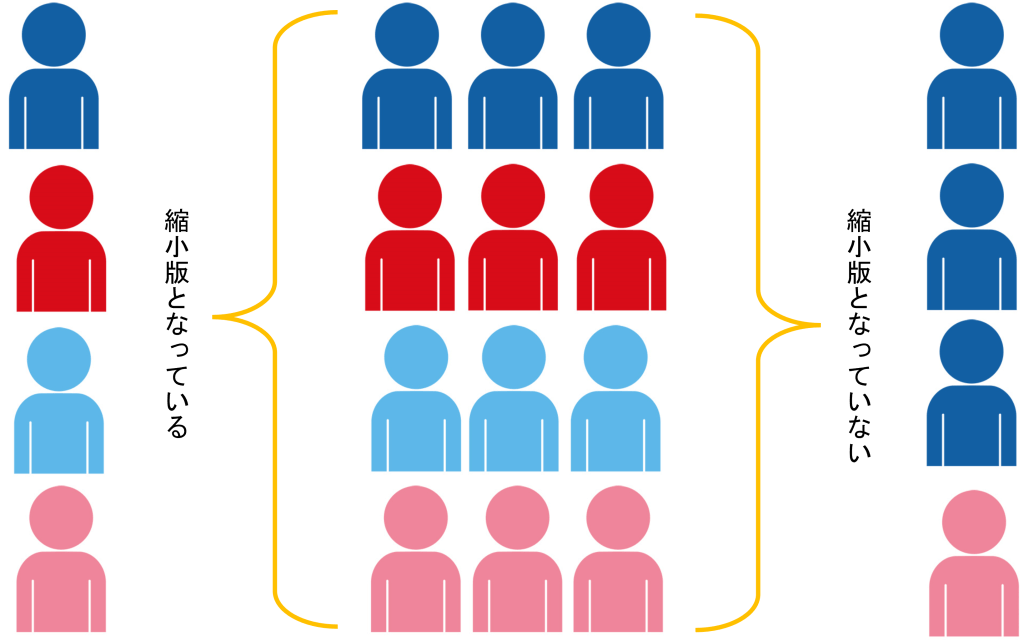
では、偏りなく母集団から標本を得る(抽出する)には、どのような方法があるでしょうか?
最も代表的な標本抽出方法を挙げてみます。
単純無作為抽出
PCなどで乱数発生させて無作為に標本を抽出する方法
系統的無作為抽出(Systematic random sampling)
母集団のすべての要素を何らかの順序に並べる。無作為に開始点を決め、n人目までをサンプルとして選択する。
層別無作為抽出(Stratified random sampling)
母集団をグループに分ける。無作為に各グループからいくつかのメンバーを選択し、標本にする。
まとめ
母集団と標本について簡単にまとめてみました。
医学統計でも「母集団と標本」は基本中の基本ですのでしっかりと理解しておきましょう😉!

コメント