
散布図とは?
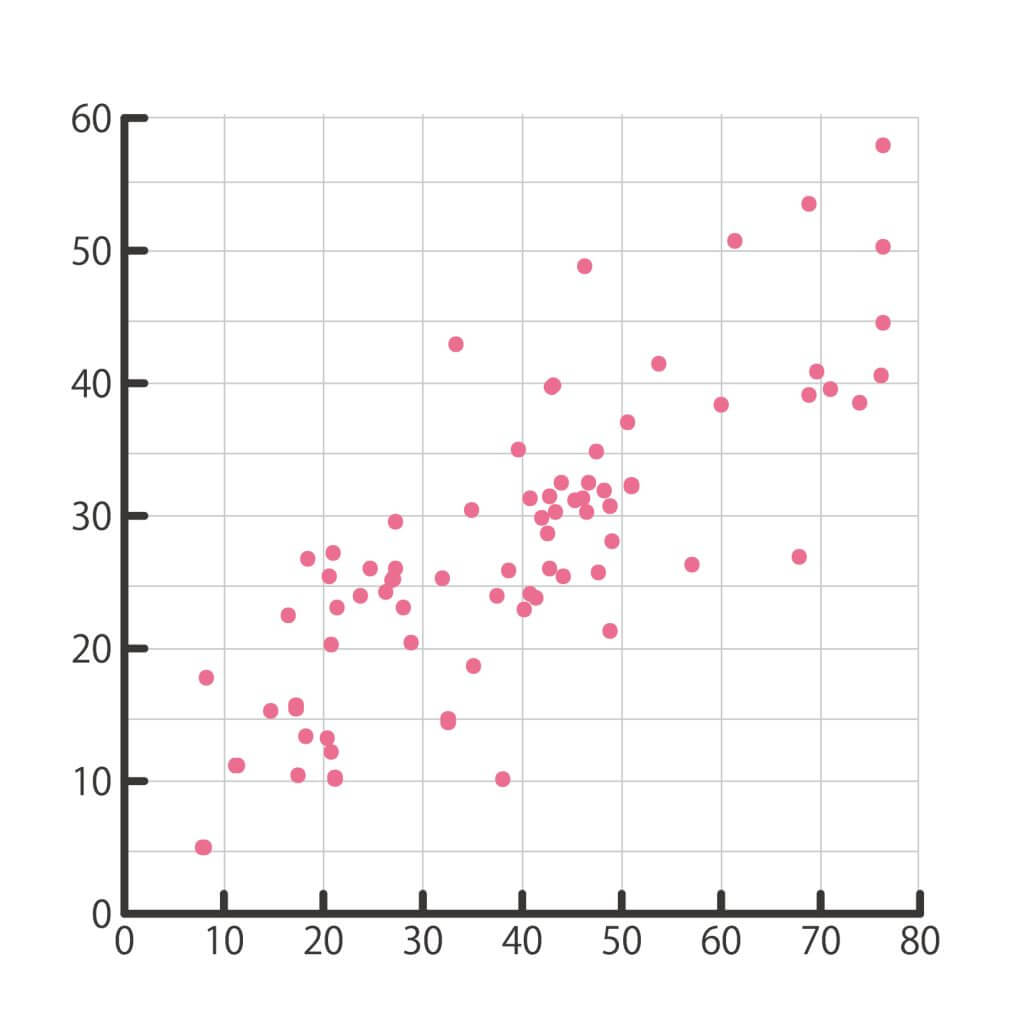
散布図とは、2つの異なる変数の値を点で表したグラフです。x軸とy軸の各点の位置は、個々のデータポイントの値を示しています。
例えば、上の散布図では架空のデータですが、この散布図から、x軸変数とy軸変数の間には、概して強い正の相関があることがわかりますね。
散布図を使う目的
散布図の主な目的は、2つの変数間の関係を観察することですね。
散布図の各点は、個々のデータポイントを表すだけでなく、データ全体として見たときのパターンからもデータの傾向を読み取ることができます。
代表的な例として、『相関関係』を扱うときに散布図はよく使われます。
この時、x軸の変数を独立変数、y軸の変数を従属変数としてグラフを描きます。
- Q独立変数?
- A
独立変数(Independent Variable) :
他の変数によって影響を受けない(独立した)変数です。独立変数は他の変数に影響を与える変数で、実験や調査などで変更される変数です。これが変わることによって、何かしらの結果や影響が生じます。例えば、ある実験で投与される薬の量などが独立変数となります。これが変わることによって、何かしらの影響が出るのです。
- Q従属変数?
- A
従属変数(Dependent Variable) は、独立変数の変化によって影響を受ける変数です。これが結果や反応となります。例えば、投薬された薬の効果によって引き起こされる反応が従属変数です。
独立変数と従属変数の関係を調査し、データを分析してその関係性を理解することが大切です。例えば、インスリン量(独立変数)と血糖値(従属変数)の関係を調べることで、治療の有効性を理解できますね。
また、変数間の関係は、正負、強弱、線形、非線形など、様々なデータの特徴を表す(読み取る)ことができます。

Rで散布図を作成
Rのplot()関数を使えば簡単に散布図を作成できます。
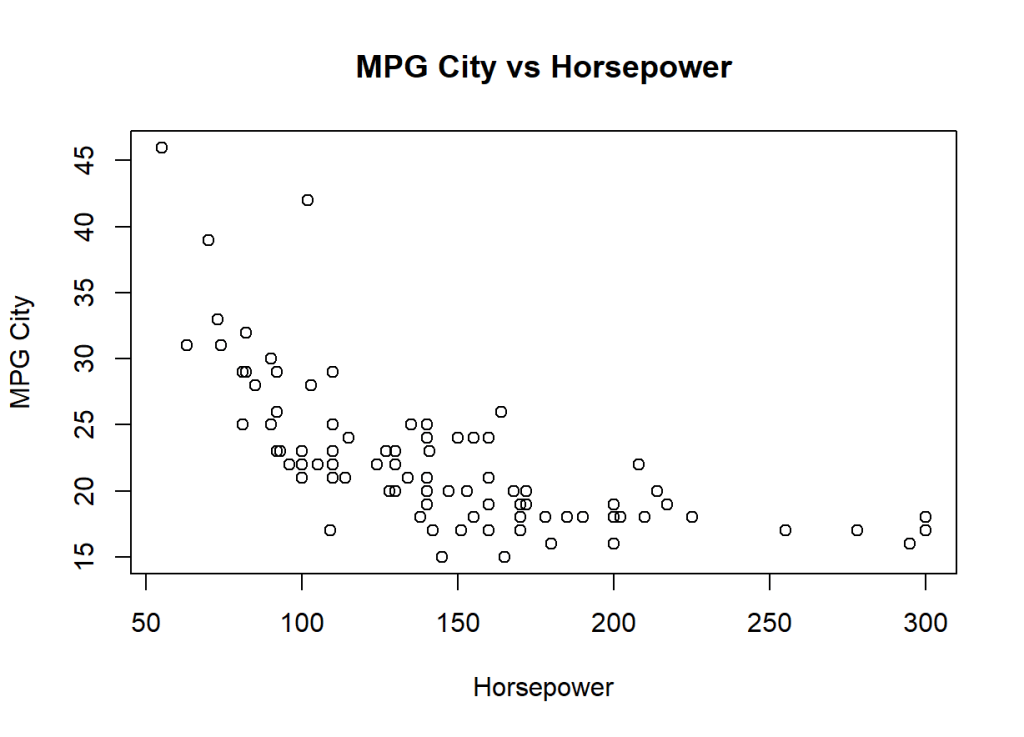
例えば、MASSパッケージに含まれるCars93データの「馬力(Horsepower)」と「燃費(MPG.city)」の関連を見るならば、
x <- Cars93$Horsepower
y <- Cars93$MPG.city
plot(y ~x, xlab="Horsepower", ylab="MPG City", main ="MPG City vs Horsepower")
とすれば、下のような散布図が表示されます。
この図から、馬力が大きくなればなるほど、燃費は悪くなる「負の相関」が読み取れます。
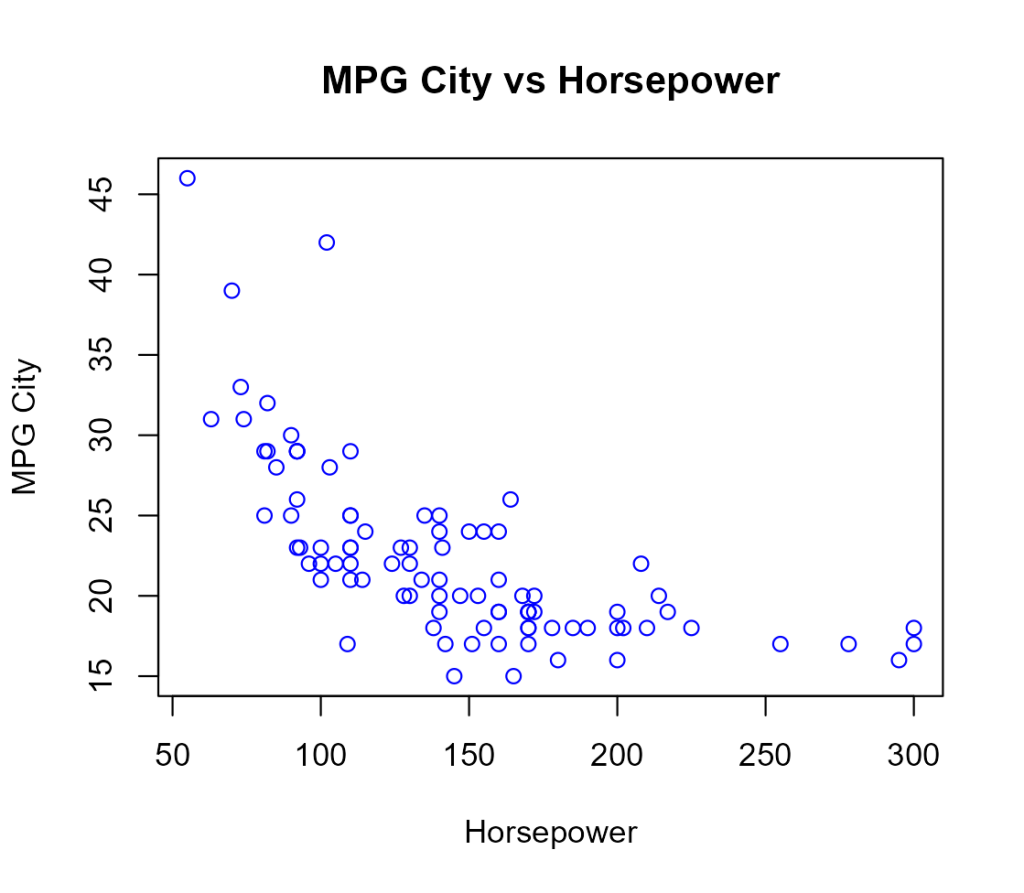
「上の散布図は白黒で少し味気ないかな?」と思いますので、色を付けてみましょう。
色を付けるには、plot()関数の引数に、「col = "色"」を追加するだけです。
では、青色にしてみます。
plot(y ~x, xlab="Horsepower", ylab="MPG City", main ="MPG City vs Horsepower", col = "blue")すると、各データポイントが青色に変わります。
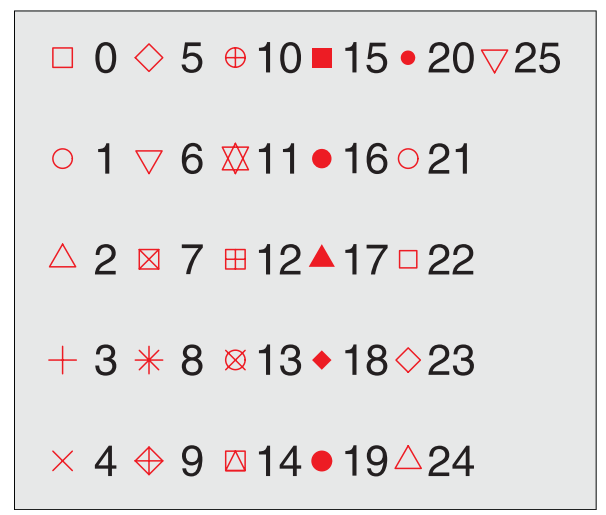
他にも、各データポイントの形を変更することも簡単です。
plot()関数の引数に、「pch=数字」を追加するだけでポイントの形を変更できます。
Rのpchには下図のように26種類ありますので、好きな形に変更が可能です。
例えば、pch=8とすれば、以下のようになります。
plot(y ~x, xlab="Horsepower", ylab="MPG City", main ="MPG City vs Horsepower", pch=8)
散布図の応用編
トレンドライン(回帰直線)の追加
散布図の変数間の予測もしくは相関関係を見るため、データに対して最適に適合するトレンドライン(回帰直線)を追加して分析できます。これにより、2変数の関係の強弱、また、トレンドラインに影響を与える外れ値の有無などの分析が可能です。
トレンドライン(回帰直線)はabline()関数とlm()関数を使うと簡単です。abline()は、R言語で直線をプロットするための関数です。これを使って、散布図やグラフに直線を追加することができます。
散布図にトレンドライン(回帰直線)を追加する方法:
1.回帰モデルを作成: lm()関数を使って回帰モデルを作成します。例えば、この回帰モデルを変数”model”に代入します。lm関数については以下の記事を参考にしてください。
2.散布図を作成: plot(x, y)で散布図を作成します。
3.回帰直線を追加: abline(model, col = "blue")で回帰モデルから得られた回帰直線をプロットします。※ここでは線の色を青に指定しています。
これで、散布図に回帰直線が追加されます。これによって、データの傾向やトレンドが視覚的に分かりやすくなります。
先程の「馬力と燃費」の散布図にトレンドライン(回帰直線)を追加してみます。
model <- lm(y ~ x)
plot(y ~ x, xlab="Horsepower", ylab="MPG City", main ="MPG City vs Horsepower")
abline(model, col = "blue")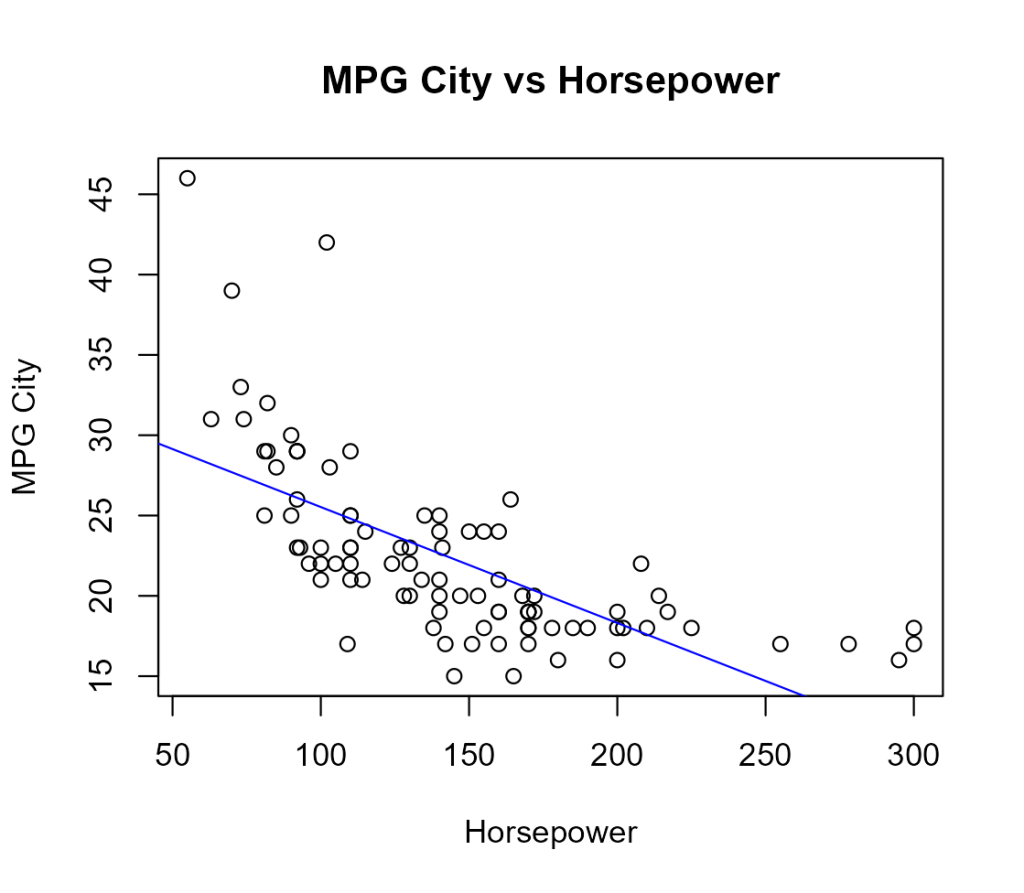
という風に、「馬力と燃費」の散布図にトレンドライン(回帰直線)が追加されました。
追記:abline()関数の基本
abline()関数は基本的に2つの主要な引数を持っています。
- a(Intercept): 切片。直線がy軸と交わる点のy座標。
- b(Slope): 傾き。直線の傾き。
基本形は以下の通りです:
abline(a = NULL, b = NULL, ...)この関数を使って直線を描くには、aとbに適切な値を設定します。例えば:
# 切片が2で傾きが1の直線を描く
abline(a = 2, b = 1, col = "red")これで、切片が2、傾きが1の直線がプロットされます。
この基本形に加えて、abline()は他にもオプション引数を持っていて、例えば"col="で線の色を指定したり、"lty="で線の種類を指定できます。
Rの散布図にカテゴリー変数を追加
2変数に含まれるカテゴリ値(例えば性別など)を点の色や形状によって表すことで、各ポイントがそれぞれのグループに属していることを簡単に示すことができます。
先程の「馬力と燃費」の散布図にシリンダー数の値を追加してみます。
これは、plot()関数の引数で使用したpchをpch=as.charactor()として、シリンダー項目を追加してみましょう。
plot(y ~ x, xlab="Horsepower", ylab="MPG City", main ="MPG City vs Horsepower",pch=as.character(Cars93$Cylinders))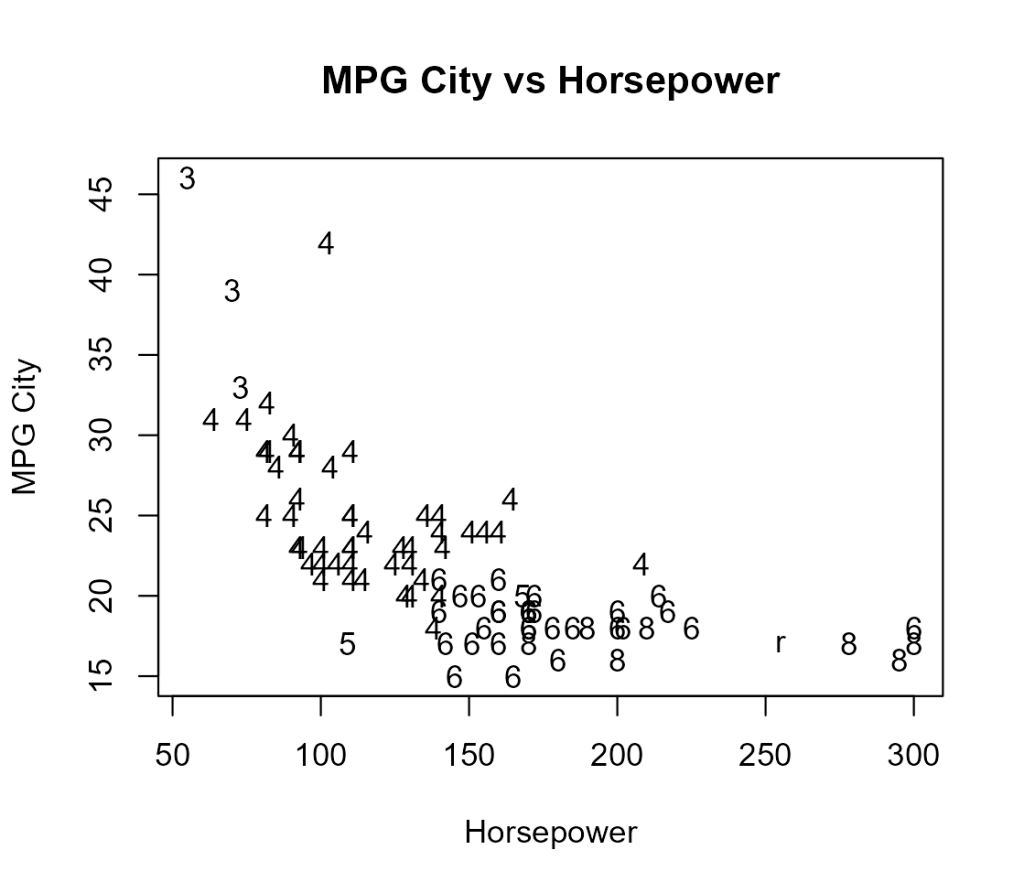
という風に、これまでの散布図にシリンダー数が追加されましたね。
こうすれば、「馬力と燃費」の関連にシリンダー数を含めた情報が読み取れます。
ggplot2を使って簡単にきれいなグラフ作成
Rの基本機能でも様々な散布図を作成できますが、さらに”ggplot2パッケージ”を使用すると、さらに詳細な変更が可能です。
まずはggplot2を使えるようにします。
もし、ggplot2をインストールしていない場合は、まず、インストールして下さいね。
install.packages("ggplot2") そして、ggplot2が使用できるようにlibrary()で読み込みます。
library(ggplot2)ggplot2でカテゴリー変数を色や形で表示
では先程、散布図にシリンダー数を数字で追加しましたが、数字がいっぱいでゴチャゴチャしているので、シリンダー数別に色別けして表示させてみましょう。
※ggplot2の詳しい説明は、またの機会にして、今回はコピペでお願いしますね🙇。
以下のコードをコピペして実行してみて下さい。
ggplot(Cars93) + geom_point(mapping = aes(x = Horsepower, y = MPG.city, color = Cylinders))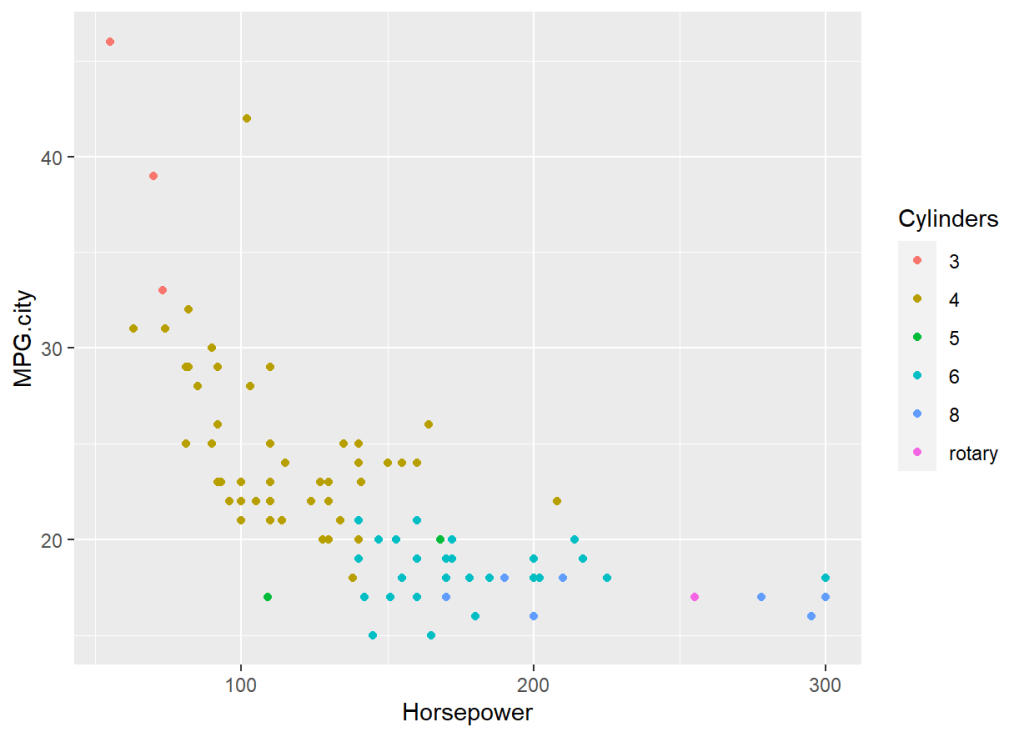
シリンダー数がカラー別に分類されました!数字で表すよりもきれいにスッキリとした図になりましたね。
今度は、シリンダー数を色別ではなく、形別で表示してみます。
ggplot(Cars93) +geom_point(mapping = aes(x = Horsepower, y = MPG.city, shape = Cylinders))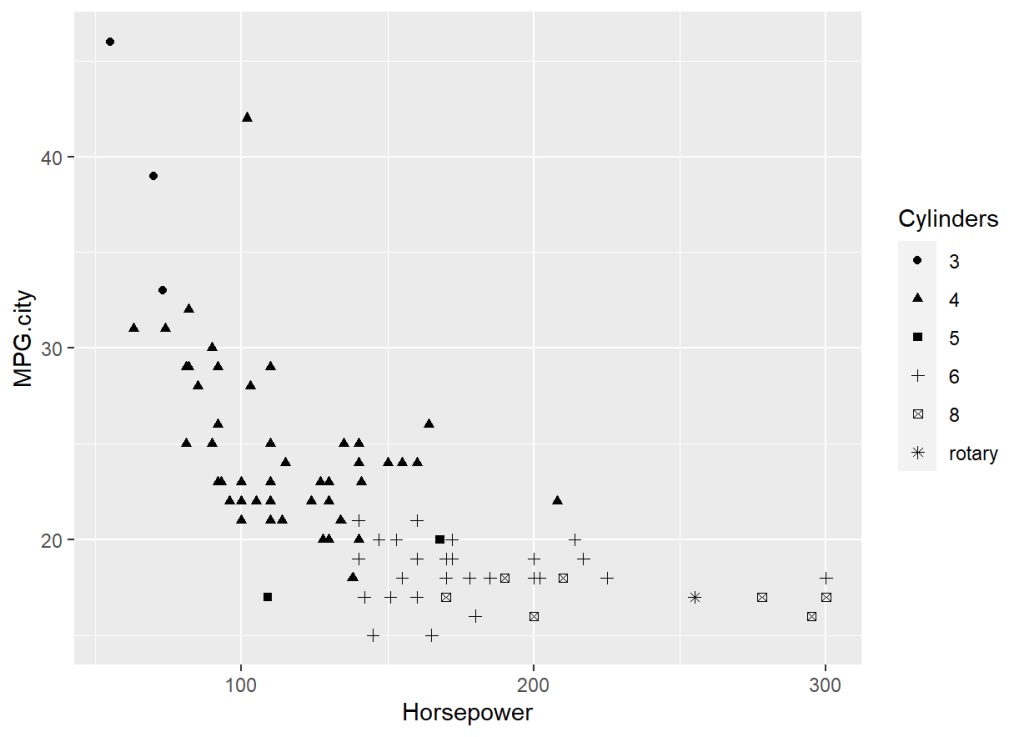
形別でシリンダー数が分類された散布図を作成できました。綺麗さ、見やすさ等は好みによりますが、ggplot2を使用すれば、簡単で綺麗なグラフ作成が可能です。
まとめ

Rを使った散布図の作成方法とその応用(トレンドライン・カテゴリー情報の追加等)についてまとめました。Rの基本機能でもグラフは作成できるのですが、ggplot2を使うと更に洗礼されたグラフを作成できます。これから徐々にggplot2についてもまとめていきますので、ご期待ください。


コメント