
Pythonでファイルを読み書きする方法がわからない…
そんな悩みを持つ初心者の方に向けて、このブログではPythonのファイル操作の基本を、コード例付きでわかりやすく解説します。
- Pythonでファイルを操作する基本(ファイルオブジェクトとopen関数)
- withブロックを使った安全なファイル操作
- ファイルに「書き込む」 ("w" モード)
- ファイルを「読み込む」 ("r" モード)
- ファイルに「データを追加する」 ("a" モード)
- ファイルを読み書きするメソッド
- 実践:テキストファイルを読み込む
- テキストファイル読み込みの基本
- データを加工して読み込む
- カンマ区切りのデータ(CSV)を分けて使う方法
- 方法1: split() を使う方法
- 方法2: csv.reader を使う方法
- テキストファイル書き込みの基本
- CSVデータの書き込み
- Google ColaboratoryでCSVファイルをダウンロード
- まとめ
Pythonでファイルを操作する基本(ファイルオブジェクトとopen関数)
ファイルオブジェクトとは

Pythonでファイルを扱うとき、初心者が最初に知っておきたい大事な概念が「ファイルオブジェクト」です。
簡単に言うと、ファイルオブジェクトとは、Pythonがファイルを操作するための窓口や手がかりのようなものです。
たとえば、ファイルオブジェクトを身近な例で説明すると、ファイル自体が「本」だとしたら、ファイルオブジェクトはその本の「コピー」に例えられます。Pythonがファイルを操作するときは、実際の本(ファイル)ではなく、その「コピー」(ファイルオブジェクト)を使います。
具体例で見てみましょう:
file = open('text.txt', 'r')
file.close()このコードでは、Pythonがtext.txtという名前のファイルをopen() を使って、読み取り専用モード(r)で開きます。そして、この操作によって作られたファイルオブジェクトをfileという変数に入れています。
ここで、fileはtext.txtという本のコピーのようなものです。このコピーを通じて、Pythonは本の内容を読んだり、場合によっては新しい内容を書き込んだりします。このように、ファイルオブジェクトを通して実際のファイルに対して操作を行うのがPythonのファイル操作の仕組みです。
こんなふうに考えると、ファイルオブジェクトが何なのか、そしてそれをどう使うのかが少しずつわかってくると思います!
ファイルを扱うときのルール
ファイルを使うときには、次の3つのステップを守りましょう:
- ファイルを開く:
open()という命令で行います。 - ファイルを操作する ファイルの中のデータを読んだり、新しいデータを書き込んだりします。
- ファイルを閉じる
close()という命令で、使い終わったファイルを閉じます。
この「開く → 操作する → 閉じる」という順番を守るのが大切なルールです。
例えば、次のように書きます:
file = open("ファイル名", "モード") # ファイルを開く
# ファイルの操作(例: 1行読む)
line = file.readline()
file.close() # ファイルを閉じる「ファイル名」について
ここでは、開いたファイルをfileという名前で扱っていますが、file以外の名前でもOKです。
「モード」について
ファイルを開くときには、モードという設定を使って、「何をするのか」を指定します。たとえば:
"r":ファイルを読み込むために開く"w":ファイルに書き込むために開く"a":ファイルの最後にデータを追加するために開く
要注意!:ファイルを閉じ忘れると何が起こる?
ファイルを開いた後にclose()を忘れてしまうと、次のような問題が起こることがあります:
- 読み込み時:ファイルが開きっぱなしになるため、他の人・プログラムがそのファイルを使えなくなる場合があります。
- 書き込み時:データの保存が正しく行われず、ファイルが壊れたり、内容が失われることがあります。
この「閉じ忘れ問題」を防ぐために、Pythonではwithという便利な構文を使う方法があります。
withブロックを使った安全なファイル操作
with構文を使うと、自動的にファイルを閉じてくれるので、close()を書き忘れる心配がなくなります。ファイルを開いて操作する処理は、次のように書き換えられます:
with open("file_name", "mode") as file:
# 以下でファイル操作を行う
line = file.readline() # ファイルから1行読み込む
print(line) # ファイルを表示する
# withブロックを抜けた時点で、自動的にファイルが閉じられるwithブロックを使うメリット
- 安全性:
close()を書き忘れる心配がない。この方法を習慣化することで、ミスを減らせます。 - 簡潔:コードがスッキリして読みやすくなる。
- エラー対策:処理中にエラーが発生しても、
withブロックを抜けるときに自動でclose()が実行されます。
つまり、withブロックの書き方では、close()を書く必要はなく、処理がwithブロックの外側から出たときに、暗黙的にclose()が実行されます。結論的には、withブロックを用いたほうが簡便なので、以降は、このwithを使った方法で記述します。
さらに詳しくファイルの読み書きの基本について学んでいきましょう。実際にコードを実行してファイル作成し、読み込んで、追加するという過程を体験してください。
ファイルに「書き込む」 ("w" モード)
次に、新しいファイルを作成してデータを書き込む例です。既存のファイルがある場合は内容が上書きされるので注意してください。
"w"モードは、ファイルが存在しない場合、新しくファイルを作成してくれるので、まず以下のコードを実行してください。
with open("text.txt", "w") as file:
# ファイルに以下を書き込む
file.write("Hello, World!\n")
file.write("This is a new file.\n")ポイント:
"w"モードは、ファイルが存在しない場合、新しく作成します。- 既存の内容は消えてしまうので注意!
ファイルを「読み込む」 ("r" モード)
"r"モードは、既にあるファイルの内容を読み取る方法です。以下のコードでは先ほど作成した”text.txt”ファイルを読み込んで、ファイルの中身を1行ずつ読み込みます。
# ファイルを読み込みモードで開く
with open("text.txt", "r") as file:
# ファイルの内容を1行ずつ読み込む
for line in file:
print(line)ポイント:
"r"モードは「読み込み専用」です。ファイルが存在しないとエラーになります。withを使うと、自動でclose()が呼ばれるので安心です。
出力:
Hello, World!
This is a new file.ファイルに「データを追加する」 ("a" モード)
最後に、既存のファイルの末尾にデータを追加する方法です。
# ファイルを追加モードで開く
with open("text.txt", "a") as file:
# ファイルの最後にデータを追加
file.write("Adding a new line.\\n")
file.write("Appending more data.\\n")ポイント:
"a"モードは、既存の内容を残したまま新しいデータを追加します。- ファイルが存在しない場合、新しく作成されます。
再度"r"モードで確認してみましょう。
出力:
Hello, World!
This is a new file.
Adding a new line.
Appending more data.
上記のように新しい文章が追加されています。
モードのまとめ
"w"モードでファイルを作成して何か書き込む。"r"モードでそのファイルを読み込む。"a"モードで新しいデータを追加する。
ファイルを読み書きするメソッド
open() 関数で取得したファイルオブジェクトは、ファイルに対して様々な操作を行うためのツールです。このオブジェクトには、ファイルからデータを読み込んだり、ファイルにデータを書き込んだりするなど、多岐にわたる機能がメソッドとして用意されています。主なメソッドを以下の表に示します
下記に示すメソッドは代表的なもののみを示しています。
| メソッド | 説明 | 例 |
|---|---|---|
| read() | ファイルの最初から最後まで、全ての内容を読み込む | data = f.read() |
| read(長さ) | ファイルの先頭から、指定した長さだけ読み込む | data = f.read(10) # 先頭から10文字読み込む |
| readline() | ファイルから1行だけ読み込む | line = f.readline() |
| readline(長さ) | ファイルの1行から、指定した長さだけ読み込む | line = f.readline(5) # 1行目から5文字読み込む |
| readlines() | ファイルの全ての内容を読み込んで、1行ずつをリストにまとめる | lines = f.readlines() |
| seek(先頭からの位置) | ファイルの読み書きの場所を、先頭から数えて指定した位置に移動する | f.seek(10) # 先頭から10文字目に移動 |
| tell() | 今、読み書きしている場所が、ファイルの先頭から何文字目か教えてくれる | position = f.tell() |
| write(データ) | ファイルにデータを書き込む | f.write("Hello, world!") |
| writelines(リスト) | リストとして構成されたデータを書き込む | f.writelines(["line1\n", "line2\n"]) |
| close() | ファイルを閉じる | f.close() |
実践:テキストファイルを読み込む
では、さらに実践を行いテキストファイルの読み書きを理解していきましょう。
サンプルファイルの準備
ここでは、下記のus_state_population.txtというテキストファイルを扱います。以下の文章をまずメモ帳ソフトなどにコピー&ペイストして ”us_state_population”という名前でテキストファイルを作成してください。
state,state code,population
Alabama,AL,4447100
Alaska,AK,626932
Arizona,AZ,5130632
Arkansas,AR,2673400
California,CA,33871648
Colorado,CO,4301261
Connecticut,CT,3405565
Delaware,DE,783600
Florida,FL,15982378
Georgia,GA,8186453
Hawaii,HI,1211537
Idaho,ID,1293953
Illinois,IL,12419293
Indiana,IN,6080485
Iowa,IA,2926324
Kansas,KS,2688418
Kentucky,KY,4041769
Louisiana,LA,4468976
Maine,ME,1274923
Maryland,MD,5296486
Massachusetts,MA,6349097
Michigan,MI,9938444
Minnesota,MN,4919479
Mississippi,MS,2844658
Missouri,MO,5595211
Montana,MT,902195
Nebraska,NE,1711263
Nevada,NV,1998257
New Hampshire,NH,1235786
New Jersey,NJ,8414350
New Mexico,NM,1819046
New York,NY,18976457
North Carolina,NC,8049313
North Dakota,ND,642200
Ohio,OH,11353140
Oklahoma,OK,3450654
Oregon,OR,3421399
Pennsylvania,PA,12281054
Rhode Island,RI,1048319
South Carolina,SC,4012012
South Dakota,SD,754844
Tennessee,TN,5689283
Texas,TX,20851820
Utah,UT,2233169
Vermont,VT,608827
Virginia,VA,7078515
Washington,WA,5894121
Washington D.C.,DC,572059
West Virginia,WV,1808344
Wisconsin,WI,5363675
Wyoming,WY,493782作成したus_state_population.txt のテキストファイルには、2000年時点のアメリカ各州の人口が記録されています。このファイルを開くことで、その内容を確認できます。
それぞれの項目は、カンマ(「,」)で区切られていて、左から、「state(州)」「state code(州コード)」「population(人口)」を示しています。
Google Colabにファイルをアップロードするのは、とっても簡単です!
まず、画面の左側にあるファイルのアイコン(フォルダのマーク)をクリックしてみましょう。
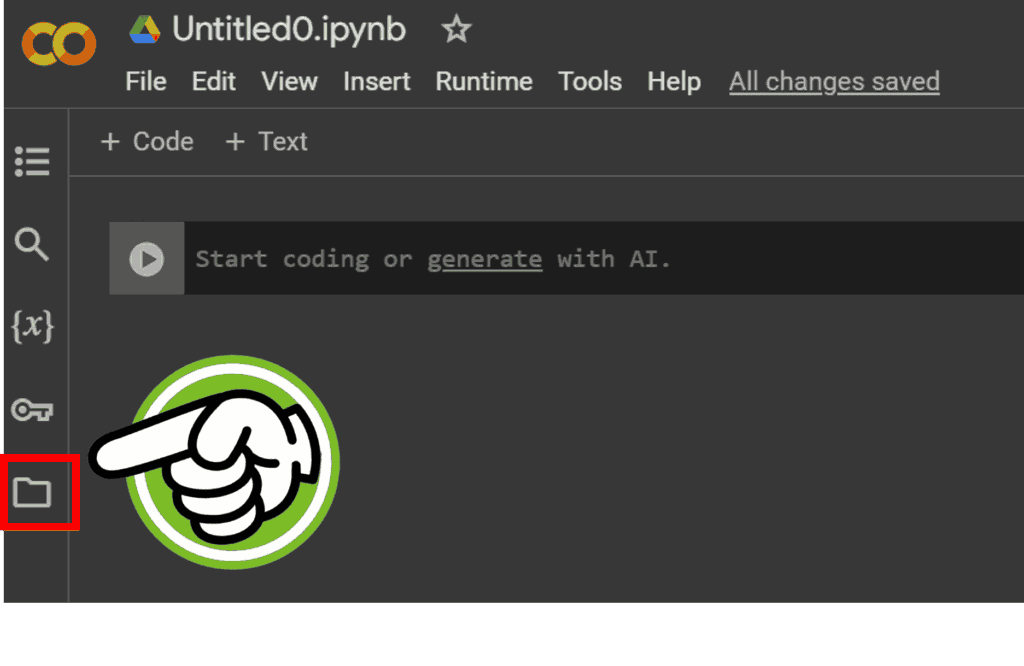
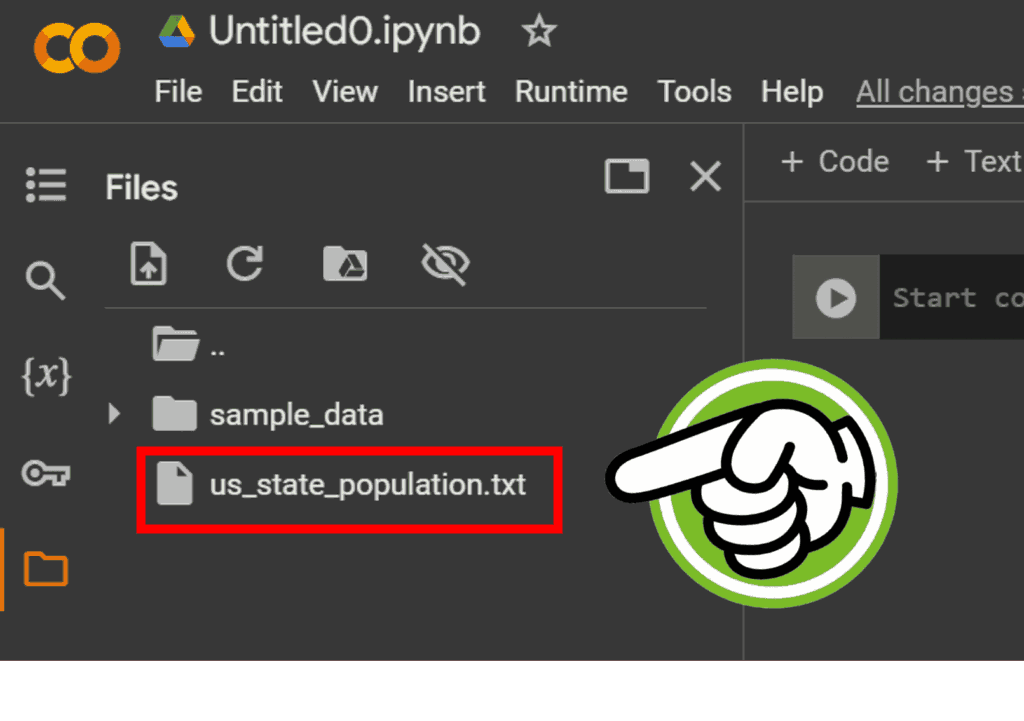
次に、左側に表示されたサイドバーに、アップロードしたいファイルをドラッグしてそのままドロップしましょう!ファイルのアップロードが終わると、下の図のようにサイドバーにファイルの名前が表示されますよ!
ファイルの中身を見たいときは、そのファイルをダブルクリックしてみてください。すると、右側(サイドバー)に中身が表示されますよ!
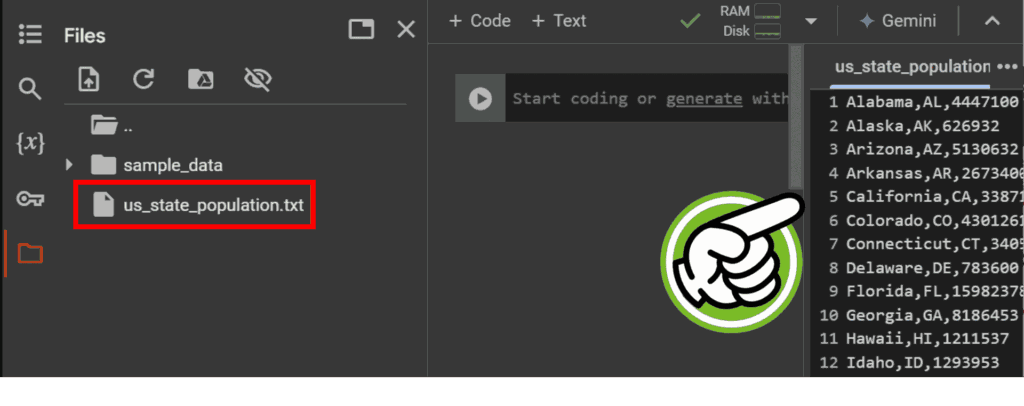
以上でファイルがアップロードされました。今回はテキストファイルをアップロードしましたが、CSV や画像などのファイルも基本的に同じ方法でアップロードできます。
全データを画面に表示する
全データを読み込む
まずは、全データを取得し、表示してみましょう。read()を使うと、全データを取得できます。たとえば次のようにすれば、全データを画面に表示できます。
with open("us_state_population.txt", "r") as practice_file:
print(practice_file.read())出力結果:
state,abbreviation,population
Alabama,AL,4447100
Alaska,AK,626932
Arizona,AZ,5130632
Arkansas,AR,2673400
California,CA,33871648
Colorado,CO,4301261
Connecticut,CT,3405565
Delaware,DE,783600
Florida,FL,15982378
Georgia,GA,8186453
Hawaii,HI,1211537
…略…
この例では、「us_state_population.txt」というファイルを読み込むために、 open("us_state_population.txt", "r") と書いています。(モードが"rt"と書かれている場合もありますが、実は”r”も”rt”も同じです)。さらにモードを省略して、ただ単に、 open("us_state_population.txt") と書くだけでもOKです。これからの説明では、簡単のためにモードを省略して書きますね!
リストとして読み込む方法
もうひとつの方法として、readlines()を使うやり方があります。この方法では、ファイルの中身をすべて読み込み、それを「リスト」(複数のデータをまとめて扱う仕組み)として取り出します。
コード例:
with open("us_state_population.txt") as practice_file:
practice_list = practice_file.readlines()
print(practice_list)出力結果:
['state,abbreviation,population\n', 'Alabama,AL,4447100\n', 'Alaska,AK,626932\n', 'Arizona,AZ,5130632\n', 'Arkansas,AR,2673400\n', 'California,CA,33871648\n', 'Colorado,CO,4301261\n', 'Connecticut,CT,3405565\n', 'Delaware,DE,783600\n', 'Florida,FL,15982378\n', 'Georgia,GA,8186453\n', 'Hawaii,HI,1211537\n', 'Idaho,ID,1293953\n', 'Illinois,IL,12419293\n', 'Indiana,IN,6080485\n', 'Iowa,IA,2926324\n', 'Kansas,KS,2688418\n', 'Kentucky,KY,4041769\n', 'Louisiana,LA,4468976\n', 'Maine,ME,1274923\n', 'Maryland,MD,5296486\n', 'Massachusetts,MA,6349097\n', 'Michigan,MI,9938444\n', 'Minnesota,MN,4919479\n', 'Mississippi,MS,2844658\n', 'Missouri,MO,5595211\n', 'Montana,MT,902195\n', 'Nebraska,NE,1711263\n', 'Nevada,NV,1998257\n', 'New Hampshire,NH,1235786\n', 'New Jersey,NJ,8414350\n', 'New Mexico,NM,1819046\n', 'New York,NY,18976457\n', 'North Carolina,NC,8049313\n', 'North Dakota,ND,642200\n', 'Ohio,OH,11353140\n', 'Oklahoma,OK,3450654\n', 'Oregon,OR,3421399\n', 'Pennsylvania,PA,12281054\n', 'Rhode Island,RI,1048319\n', 'South Carolina,SC,4012012\n', 'South Dakota,SD,754844\n', 'Tennessee,TN,5689283\n', 'Texas,TX,20851820\n', 'Utah,UT,2233169\n', 'Vermont,VT,608827\n', 'Virginia,VA,7078515\n', 'Washington,WA,5894121\n', 'Washington D.C.,DC,572059\n', 'West Virginia,WV,1808344\n', 'Wisconsin,WI,5363675\n', 'Wyoming,WY,493782']出力を見てみると、ファイルの中のそれぞれの行がリストの中に1つずつ入っているのがわかります。
ポイント:
- 各行の最後にある
\nは「改行」を意味しています。
リストの形で読み込むと、データを行ごとにまとめて扱えるので便利ですよ!
テキストファイル読み込みの基本
1行ずつファイルを読み込む方法
テキストデータを扱うとき、全部を一気に読むのではなく、1行ずつ順番に読みたい場合があります。特に、大きなファイルを扱うときは、この方法が便利です。ここでは、1行ずつファイルを読み込む2つの方法を紹介します。
方法1:1行ずつループで読み込む方法
readline()を使う
readline()は、ファイルから1行だけ読み込みます。そして、ファイルの終わりまで来たときには「空の文字列」を返します。この仕組みを利用して、ループ処理で1行ずつ読み込み、全てのデータを表示することができます。
while文もしくはfor文を使って実行してみましょう。
while文を使う場合
with open("us_state_population.txt") as practice_file:
while True:
each_line = practice_file.readline() # 1行読み込む
print(each_line) # 読み込んだ行を表示する
if not each_line: # 読み込む行がなくなったら(空文字列になったら)
break # ループを終了するこの方法では、while True:で無限ループを作り、readline()で1行ずつ読み込みます。そして、if not practice_list:でファイルの終わりをチェックして、ループを止めます。
for文を使う場合
with open("us_state_population.txt") as practice_file:
for each_line in practice_file: # ファイルから1行ずつ自動で読み込む
print(each_line) # 読み込んだ行を表示するこの方法では、for line in fを使うと、自動的に1行ずつ読み込んでくれます。ファイルの終わりになったら、自動でループが終了します。
出力:
while文もしくはfor文のどちらの方法でも、以下のような出力が得られます:
state,abbreviation,population
Alabama,AL,4447100
Alaska,AK,626932
Arizona,AZ,5130632
Arkansas,AR,2673400
California,CA,33871648
Colorado,CO,4301261
Connecticut,CT,3405565
Delaware,DE,783600
Florida,FL,15982378
Georgia,GA,8186453
Hawaii,HI,1211537
…略…
どちらを使えばいいの?
while文は、より細かい制御が必要な場合に使います(たとえば、特定の条件でループを終了したいとき)。for文は、簡単で読みやすいコードが書けます。特に、1行ずつ単純に処理する場合はおすすめです。
どちらの方法も結果は同じですが、コードの「読みやすさ」や「使いやすさ」を考えて選ぶとよいでしょう!
方法2:リストとしてファイル全体を読み込む方法
もう1つの方法として、前のセクションで紹介したreadlines()を使う方法があります。この方法では、ファイルの中身全体を一括で読み込み、リスト形式で取得します。それぞれの行がリストの1つの要素として格納されるため、リストとして操作できます。
ただし、この方法はファイル全体をメモリに読み込むため、大きなファイルではメモリを圧迫する可能性があります。したがって、小さなファイルを扱う場合に適しています。
readlines()を使う場合
with open("us_state_population.txt") as practice_file:
whole_list = practice_file.readlines() # ファイル全体をリストとして読み込む
print(whole_list)出力結果:
['state,abbreviation,population\n', 'Alabama,AL,4447100\n', 'Alaska,AK,626932\n', 'Arizona,AZ,5130632\n', 'Arkansas,AR,2673400\n', 'California,CA,33871648\n', 'Colorado,CO,4301261\n', 'Connecticut,CT,3405565\n', 'Delaware,DE,783600\n', 'Florida,FL,15982378\n', 'Georgia,GA,8186453\n', 'Hawaii,HI,1211537\n', 'Idaho,ID,1293953\n', 'Illinois,IL,12419293\n', 'Indiana,IN,6080485\n', 'Iowa,IA,2926324\n', 'Kansas,KS,2688418\n', 'Kentucky,KY,4041769\n', 'Louisiana,LA,4468976\n', 'Maine,ME,1274923\n', 'Maryland,MD,5296486\n', 'Massachusetts,MA,6349097\n', 'Michigan,MI,9938444\n', 'Minnesota,MN,4919479\n', 'Mississippi,MS,2844658\n', 'Missouri,MO,5595211\n', 'Montana,MT,902195\n', 'Nebraska,NE,1711263\n', 'Nevada,NV,1998257\n', 'New Hampshire,NH,1235786\n', 'New Jersey,NJ,8414350\n', 'New Mexico,NM,1819046\n', 'New York,NY,18976457\n', 'North Carolina,NC,8049313\n', 'North Dakota,ND,642200\n', 'Ohio,OH,11353140\n', 'Oklahoma,OK,3450654\n', 'Oregon,OR,3421399\n', 'Pennsylvania,PA,12281054\n', 'Rhode Island,RI,1048319\n', 'South Carolina,SC,4012012\n', 'South Dakota,SD,754844\n', 'Tennessee,TN,5689283\n', 'Texas,TX,20851820\n', 'Utah,UT,2233169\n', 'Vermont,VT,608827\n', 'Virginia,VA,7078515\n', 'Washington,WA,5894121\n', 'Washington D.C.,DC,572059\n', 'West Virginia,WV,1808344\n', 'Wisconsin,WI,5363675\n', 'Wyoming,WY,493782']Pythonでファイルを読み込む方法のまとめ
- 1行ずつ読み込む方法 (
while文やfor文を使う): 大きなファイルを効率よく処理したいときに便利です。 - リストとして一括で読み込む方法 (
readlines()): ファイルサイズが小さく、全データをまとめて扱いたいときに便利です。
どちらの方法を使うかは、ファイルのサイズや処理内容によって使い分けると良いでしょう。また、コードの見やすさや効率性も考慮して選んでください!
データを加工して読み込む
データを加工して読み込みたいこともあります。いくつかの方法を例示します。
見出しの行を読み飛ばす
データによっては1行目が見出し行となっている場合があります。それを読み飛ばしてデータを読み取りたい場合は、最初に1回、next()を、先に実行して読み飛ばします。
サンプルコード
with open("us_state_population.txt") as practice_file:
next(practice_file) # 1行目を読み飛ばす
for line in practice_file:
print(line.strip()) # 各行を出力(改行を削除)
上記の例では、
next()を使うと、ファイルの最初の1行を簡単に読み飛ばすことができます。for line in practice_file2行目以降をループで処理します。line.strip()行末の改行文字や余分な空白を削除して出力します。
実際にコードを実行すると以下のような結果が出力されます。
Alaska,AK,626932
Arizona,AZ,5130632
Arkansas,AR,2673400
California,CA,33871648
Colorado,CO,4301261
Connecticut,CT,3405565
Delaware,DE,783600
Florida,FL,15982378
Georgia,GA,8186453
Hawaii,HI,1211537
…略…
一部のデータだけを表示する
全部を処理するのではなく、一部のデータだけを処理したいこともあります。そのようなときは、たとえば、処理した回数をカウントして、一定数処理したときにループを終了するようなプログラムを書きます。
以下は、処理したい回数をカウントし、一定回数処理したらループを終了するプログラムの例です。
max_lines = 10 # 処理したい行数
count = 0 # 処理した行数をカウント
with open("us_state_population.txt") as practice_file:
next(practice_file) # 1行目を読み飛ばす(見出し行)
for line in practice_file:
print(line.strip()) # 各行を処理(改行を削除して出力)
count += 1 # カウントを増やす
if count >= max_lines:
break # 指定された行数に達したらループを終了max_lines処理したい行数を指定します。この例では、10行分のデータを処理します。- カウント変数(
count) 各行を処理するたびにcountを1増やし、指定された行数に達するとbreakでループを終了します。 next(practice_file)1行目を読み飛ばします(見出し行をスキップ)。breakif count >= max_linesの条件を満たした場合、breakでループを強制終了します。
このプログラムを実行すると、最初の10件のデータが処理され、以下のように出力されます:
Alabama,AL,4447100
Alaska,AK,626932
Arizona,AZ,5130632
Arkansas,AR,2673400
California,CA,33871648
Colorado,CO,4301261
Connecticut,CT,3405565
Delaware,DE,783600
Florida,FL,15982378
Georgia,GA,8186453カンマ区切りのデータ(CSV)を分けて使う方法
テキストデータが「Alaska, AK,626932」のようにカンマ(,)で区切られていることがあります。このようなデータは「CSVデータ(Comma Separated Values)」と呼ばれます。
CSVデータでは、例えば「state」「abbreviation」「population」と、データの各部分がカンマで分かれています。
ここでは、CSVデータを分割して使う2つの方法を説明します。
方法1: split() を使う方法
まず、文字列のsplit()という機能を使って、データをカンマで分割する方法です。
サンプルコード
with open("us_state_population.txt") as file:
next(file) # 1行目(見出し行)をスキップ
for i, line in enumerate(file):
parts = line.strip().split(",") # カンマで分割
print(parts) # 分割されたデータを表示
if i >= 9: # 最初の10行だけ処理
breakline.strip()各行の余分な空白や改行を取り除きます。split(",")行をカンマで分割し、それぞれをリストとして扱います。- リストの中身
parts[0]: 州名(例: "Alaska")parts[1]: 州コード(例: "AK")parts[2]: 人口(例: "626932")
方法2: csv.reader を使う方法
次に、Pythonのcsvという便利なモジュールを使う方法です。
サンプルコード
import csv
with open("us_state_population.txt") as file:
use_reader = csv.reader(file) # CSVデータを読み込む
next(use_reader) # 1行目(見出し行)をスキップ
for i, row in enumerate(use_reader):
print(row) # 分割されたデータを表示
if i >= 9: # 最初の10行だけ処理
breakcsv.readerファイルを自動的にカンマで分割してくれます。- 改行の処理が不要
csv.readerを使うと、改行を取り除くstrip()がいりません。 - リストの中身
row[0]: 州名(例: "Alaska")row[1]: 州コード(例: "AK")row[2]: 人口(例: "626932")
とちらの方法でも以下のような出力結果が得られます。
['Alabama', 'AL', '4447100']
['Alaska', 'AK', '626932']
['Arizona', 'AZ', '5130632']
['Arkansas', 'AR', '2673400']
['California', 'CA', '33871648']
['Colorado', 'CO', '4301261']
['Connecticut', 'CT', '3405565']
['Delaware', 'DE', '783600']
['Florida', 'FL', '15982378']
['Georgia', 'GA', '8186453']
どちらを使えばいいの?
- データがカンマで区切られている場合は、
csv.readerを使うのが簡単で便利です。 - 他の文字(例: タブやスペース)で区切られている場合は、
split()が役立ちます。
テキストファイル書き込みの基本
ファイルの読み込み方法を説明したところで、今度は、ファイルへの書き込み方法を説明します。
Pythonでテキストファイルにデータを書き込むには、open() 関数で、書き込みモードに "w"(上書き)や "a"(追記)を指定します。
基本の書き込み
以下のコードをGoogle Colaboratoryで実行してみましょう。
# "w" モードで新しいファイルを作成し、書き込み
with open("sample.txt", "w") as file:
file.write("こんにちは、Python!\n")
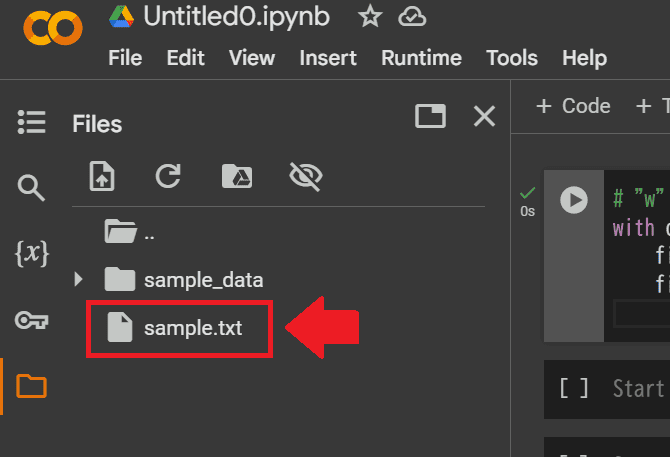
file.write("ファイル書き込みを学びましょう。\n")前述したように"w" モードは、新しいファイルを作成してデータを書き込む方法でしたね。また既存のファイルがある場合は内容が上書きされるので注意してください。
このコードを実行すると、下図のようにsample.txt というファイルが作成されます。
書き込んだファイルの確認
Google Colaboratoryでは、以下のコマンドを使ってファイルの内容を確認できます。
# 書き込んだファイルを読み取って表示
with open("sample.txt", "r") as file:
content = file.read()
print(content)確認してみると以下のように実行した2行のテキストが書き込まれています。
出力:
こんにちは、Python!
ファイル書き込みを学びましょう。追記モード("a")を使う
"a" モードを使うと、既存のファイルの末尾にデータを追加できます。
# "a" モードでファイルの末尾に追記
with open("sample.txt", "a") as file:
file.write("追記された行です。\n")再度ファイルを読み込んで内容を確認してみましょう。
# 書き込んだファイルを読み取って表示
with open("sample.txt", "r") as file:
content = file.read()
print(content)出力:
こんにちは、Python!
ファイル書き込みを学びましょう。
追記された行です。という風に3行目が追加されています。
複数行の書き込み
writelines() を使うと、リストに入れた複数の文字列をまとめて書き込めます。
lines = ["1行目\n", "2行目\n", "3行目\n"]
with open("multi_lines.txt", "w") as file:
file.writelines(lines)この場合、リストの各要素がそのまま書き込まれます。
with open("multi_lines.txt", "r") as file:
content =file.read()
print(content)出力:
1行目
2行目
3行目Google Colaboratoryでファイルをダウンロード
作成したファイルをローカルにダウンロードするには、以下のコードを実行します。
from google.colab import files
files.download("sample.txt")これで、Google Colaboratoryでのファイル書き込みの基本が学べました!
CSVデータの書き込み
CSV(カンマ区切り値)ファイルは、データを整理して保存するのに便利な形式です。Pythonでは、csv モジュールを利用した方法でCSVデータを書き込むことができます。Google Colaboratoryを使って、それぞれの方法を実践してみましょう。
CSVデータの書き込み( csv.writer を使う方法)
Pythonの csv モジュールを使うことで、安全にCSVファイルを作成できます。writerows() を使うと、リスト内の複数行のデータを一度に書き込めます。
以下のコードで、リストのデータをCSV形式でファイルに保存できます。
import csv
state_population = [
['Alabama', 'AL', '4447100'],
['Alaska', 'AK', '626932']
]
with open("data1.csv", "w", newline="") as file:
writer = csv.writer(file)
writer.writerows(state_population)内容を確認
# ファイルの内容を確認
with open("data1.csv", "r") as file:
print(file.read())出力:
Alabama,AL,4447100
Alaska,AK,626932数字についても同様です。
import csv
num_data = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
with open("data2.csv", "w", newline="") as file:
writer = csv.writer(file)
writer.writerows(num_data)確認してみましょう。
# ファイルの内容を確認
with open("data2.csv", "r") as file:
print(file.read())出力:
1,2,3
4,5,6
7,8,9この方法を使うと、カンマや改行を含むデータでも問題なくCSVファイルに保存できます。
Google ColaboratoryでCSVファイルをダウンロード
作成したCSVファイルをローカルPCにダウンロードしたい場合は、以下のコードを実行します。
from google.colab import files
files.download("data2.csv")これで、Google Colaboratoryを使ったCSVファイルの書き込み方法が理解できましたね。
まとめ

このレッスンでは、テキストファイルの読み書きに関する方法や手順について学びました。具体的には、テキストファイルをプログラムで操作する際の基本的な仕組みや、読み込む際の手順、そして書き込む際の注意点などを一通り確認しました。今回、学んだ内容の中で理解が曖昧な部分や、もう少し練習が必要だと感じる点があれば、時間を取ってしっかりと復習することをおすすめします。基礎がしっかり身についていることで、これから先のより高度な内容をスムーズに学ぶ土台が築けます。焦らず、確実に進めていきましょう!


コメント