
データ分析を実施する時にまず最初にしなければならないことは、集めたデータを解析しやすい構造に形成することです。そこで、Rでデータ解析する際に使用するデータ型とデータ構造のついて説明します。
Rのデータ型とデータ構造とは?
基本的なデータ型:
- 数字:Numeric
- 文字:Charactor
- 倫理:Logic
基本的なデータ構造:
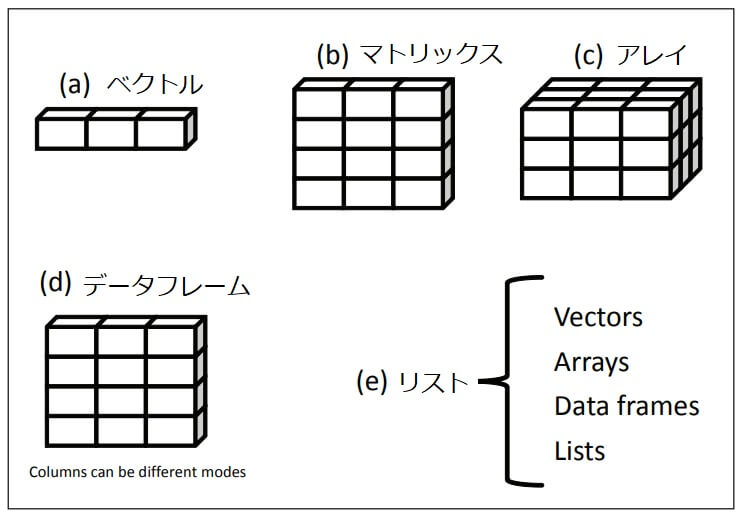
- ベクトル (vector)
- マトリックス (matrix)
- アレイ(array)
- データフレーム (data frame)
- ファクター (facotr)
- リスト (list)
これらのデータ型とデータ構造についてしっかりと理解しておけば、今後もRの動作を理解する上で非常に役に立ちます。少し長くなりますが、出来るだけ分かりやすく解説しますので、ゆっくりと時間をかけて内容を把握してください。
サンプルデータ作成
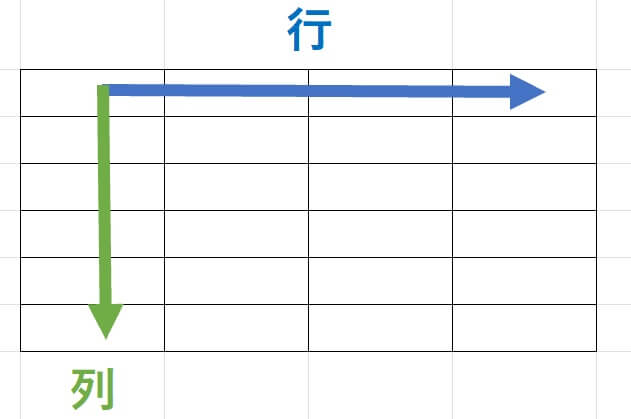
まず収集されたデータ(データセット)は通常、横方向を「行」、縦方向を「列」といい、行方向に観測値、列方向に変数を表します。
以下に架空のコロナウイルス検査データを作成してみます。
感染者番号(ID)、年齢(age)、ワクチン接種(有り:T、無し:F)タイプ(α株・β株)、状態:(軽症:mild、中等度:moderate、重症:severe、集中治療:critical)としています。
| ID | age | vaccine | type | condition |
| 1 | 25 | F | alpha | severe |
| 2 | 34 | T | beta | mild |
| 3 | 28 | T | beta | moderate |
| 4 | 52 | F | alpha | moderate |
| 5 | 71 | T | alpha | critical |
ちなみにサンプルデータのようなデータ構造をR言語では、「データフレーム」と呼びます。データフレームでは様々なデータ型を扱えることから、Rでデータを扱う上で非常に大きな柔軟性をもたらしてくれます。(これについての詳細はデータフレームの項目で説明します。)
Rで扱うデータ型
上のデータセットを例に、データ型について理解してみましょう。
まずそれぞれのデータの尺度は、
- ID・vaccine・type:名義尺度 (IDはケース識別子なので名義尺度です)
- age:比例尺度
- condition:順序尺度
です。
変数の尺度について簡単にまとめます。
名義尺度は、データをカテゴリーに分類するための尺度であり、順序や大小の情報はありません。例えば、血液型や性別が挙げられます。
順序尺度は、データの順序や序列に意味がある尺度ですが、順序間の間隔は一定ではありません。例えば、満足度や好感度といったランキングが順序尺度です。
間隔尺度は、データの間隔が一定であり、順序も意味がある尺度です。しかし、絶対的なゼロ点は存在しないため、比率を求めることはできません。摂氏温度やIQスコアが間隔尺度の例です。
比尺度は、データの順序や間隔に加えて、絶対的なゼロ点も持つ尺度です。これにより、データの比率を求めることが可能です。例えば、身長や体重が比尺度の例です。
そして、Rのデータ型には数値 (numeric)、文字 (charactor)、論理(logical) 型などがあります。上のサンプルデータで言えば、
- IDとage:数値型
- vaccine:論理型
- typeとcondition:文字型
になります。
Rのデータ型の基本
数値型(numeric)のデータとは整数(integer)と実数(double)の両方を扱います。
例えば、
x <- c(1, 4, 5, 10, 3)
y <- c(1.3, -10, 5, 6,11)みたいな感じです。
文字型のデータとは文字 (charactor)を扱い、Rでは、ダブルクオーテーションマーク(" ")で囲まれたものを指します。
例えば、
x <- c("Tomo", "Mika", "Ken")は文字型です。
論理型のデータとは「真(TRUE)」「偽(FALSE)」で扱われるデータです。また、論理型のTRUE=1、FALSE=0と数字に置き換えて分析することも頻繁に使われます。
例えば、
y <- c(T,F,T,T)という風にTRUEはT、FALSEはFと省略して入力されます。
※省略せずに、y <- c(TRUE,FALSE,TRUE,TRUE)でも大丈夫です。
TRUE=1、FALSE=0と捉えることも可能ですので、上のyを合計すると、
sum(y)
[1] 3とすれば、TRUE=1で合計された3が表示されます。
Rのデータ型の確認方法
データ型を調べる方法としてRでは「typeof関数」と「mode関数」があります。例えば上の例を使って、「typeof関数」と「mode関数」でデータ型を確認してみましょう。
返り値の型:
typeof関数: オブジェクトの内部表現に基づいて、データの基本的な型を示します。例えば、"double"や"character"などが返ります。mode関数: オブジェクトの利用可能なクラスのうち、最初に見つかったクラスを示します。データ型をより高次の概念で表現します。例えば、"numeric"や"character"などが返ります。
x <- c(1, 4, 5, 10, 3)
typeof(x)
[1] "double"
mode(x)
[1] "numeric"
y <- c(1.3, -10, 5, 6,11)
typeof(y)
[1] "double"
mode(y)
[1] "numeric"上の例では、typeof関数は"double"、mode関数は"numeric"を返しました。
文字型や論理型についても同様に試してみましょう。
x <- c("Tomo", "Mika", "Ken")
typeof(x)
[1] "character"
mode(x)
[1] "character"
y <- c(T,F,T,T)
typeof(y)
[1] "logical"
mode(y)
[1] "logical"と、いう風にデータ型の確認ができましたね。
Rで扱うデータ構造
Rには、ベクトル、マトリックス、アレイ、データフレーム、リストなど、データ を保持するための様々なデータ構造があることは冒頭で触れました。以下の図はそれぞれのデータ構造を資格的に理解しやすく表したものです。
それぞれのデータ構造は、保持できるデータの種類、作成方法、構造の複雑さ、個々の要素を識別してアクセスするための表記法などの点で異なっています。
ベクトル (vector)
まず、最も基本的なベクトル(vector)から順番に各構造を見ていきましょう。
ベクトルは1次元の配列で、数値型データ、文字型データ、論理型データのいずれか1つを格納することができます。ベクトルを形成するには、「c()関数」を使用します。例えば、
x <- c(1, 2, 3,4,5)
y <- c("one", "two", "three", "four", "five")
z <- c(T, T, F, T, F)などです。
上の例では、xは数値型ベクトル、yは文字型ベクトル、zは論理型ベクトルとなります。
ここで最も重要なのは、ベクトルが含むことのできるデータは、1つの型(数値、文字、論理型のいずれか1つ)でなければならないことです。下の例のように、ベクトル内に異なる形のデータをそれぞれのデータ型の状態で混在させることはできません。
a <- c(1, 2, "one", "two", T, F)上のコードを実行すると
print(a)
[1] "1" "2" "one" "two" "TRUE" "FALSE"と、全てがCharacter型に強制変換されています。
ベクトル内の要素を確認する方法
上の例のようにデータが少ない場合は、データを目で見るだけでもベクトル内の要素を確認できますが、研究や調査では100以上もしくは1000や10000以上のデータを一つのベクトルが含んでいる場合もあります。これらの膨大なデータを視覚的に探すのは難しいですね。その場合、任意の番号のベクトル要素を参照するためにインデックス([ ]:角括弧 )を使用します。
例えば、
x <- c(1, 2, 3, 4, 5)
x[2] #2番めの要素を取り出す
[1] 2という風にベクトル要素の”2”が返ってきます。(※Rではデータを1番目から数えます。Pythonなどの言語では0番目から数えるので間違わないように注意してくださいね。)
また、x[2:4]とコロン(:)演算子を使えば連続した番号を指定できます。この場合、2〜4番目の要素を指定して要素を取り出すことができます
x[2:4] #2~4番目の要素を取り出す
[1] 2 3 4
行列(マトリックス 、 matrix)
行列(マトリックス)は、各要素が同じデータ型(数値、文字、論理)を持つ2次元の配列です。行列は,「matrix関数」を使って作成します。
一般的な行列のフォーマットは以下のようになります。
x <- matrix(vector, nrow=number_of_rows, ncol=number_of_columns, byrow=T or F, dimnames=list(char_vector_rownnams, char_vector_colnames)))
- vector:ベクトル(もしくはデータ)
- nrow・ncol :number of row・number of columnの略。行と列の次元を指定。つまり「横と縦」の行列を指定
- byrow : ベクトル(データ)の並べ方を指定します:
- データを行単位で並べる 場合、byrow=TRUE
- データを列単位で並べるか場合、byrow=FALSE (デフ ォルトは列単位となっています。)
- dimnames :行や列の名前を設定
例として5X4の行列(matrix)を作成してみます。
まずは、行単位で並べた場合、
rnames<-c("行1", "行2", "行3", "行4", "行5") #行の名前
cnames<-c("列1", "列2", "列3", "列4") #列の名前
x <- matrix(1:20, nrow = 5, ncol = 4, byrow = TRUE, dimnames = list(rnames, cnames))
x
列1 列2 列3 列4
行1 1 2 3 4
行2 5 6 7 8
行3 9 10 11 12
行4 13 14 15 16
行5 17 18 19 20次に、列単位で並べた場合、
y <- matrix(1:20, nrow = 5, ncol = 4, byrow = FALSE, dimnames = list(rnames, cnames))
y
列1 列2 列3 列4
行1 1 6 11 16
行2 2 7 12 17
行3 3 8 13 18
行4 4 9 14 19
行5 5 10 15 20行列(matrix)は2次元構造のベクトルと考えて下さい。なので、ベクトルと同様に1つのデータ型しか含むことができません。もしデータ構造が2次元を超える場合は、後述するアレイ(array)を使用します。また複数のデータ型がある場合は、行列ではなく、後述するデータフレームを使用します。
行列内の要素の指定
ベクトルの時と同様に、インデックス([ ]:角括弧)を使って、行列の行・列の要素を特定することができます。
X[i,]は 行列Xの「i行目」、X[,j]は「j列目」、X[i, j]は「i行のj列目」の要素をそれぞれ意味します。
複数の行または列を選択するには、コロン(:)やc( )を使用すれば簡単です。
例えば、以下の行列(matrix)から行、列、そして行×列を指定して要素を取り出します。
x <- matrix(1:10, nrow=2)
x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10 x[2,] #2行目の要素を全て選択
[1] 2 4 6 8 10x[,2] #2列目を全て選択
[1] 3 4x[1,4] #1行目×4列目の要素を選択
[1] 7x[1, c(4,5)] #1行目×4・5列目の要素を選択
[1] 7 9マトリックス内の要素の指定はベクトルの要素指定が2次元になったととらえればいいですよ。
アレイ(array、配列 )
アレイ(array、配列)は行列(matrix)に似ていますが、2次元以上の多次元のデータ形を持つことができます。
アレイは「array関数」を使い、一般形は以下のようになります。
x <- array(vector, dimensions, dimnames)
- vector :ベクトル(もしくはデータ)
- dimensions :アレイの各次元の数。例えば、c(2, 3, 4)ならば、2×3の行列が4つ
- dimnames :各次元名
例として以下に3次元(2x3x4)のアレイ(array)を作成してみます。
dim1 <- c("X1", "X2")
dim2 <- c("Y1", "Y2", "Y3")
dim3 <- c("Z1", "Z2", "Z3", "Z4")
z <- array(1:24, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))z
, , Z1
Y1 Y2 Y3
X1 1 3 5
X2 2 4 6
, , Z2
Y1 Y2 Y3
X1 7 9 11
X2 8 10 12
, , Z3
Y1 Y2 Y3
X1 13 15 17
X2 14 16 18
, , Z4
Y1 Y2 Y3
X1 19 21 23
X2 20 22 24このように、アレイは行列を拡張したものだと考えると理解しやすいと思います。ベクトル、マトリックスと同様に、アレイも格納できるのは、一種類のデータ型のみとなります。
多次元になってくると視覚的なイメージが難しくなってきますね。
データフレーム (data frame)
データフレームは、これまでのデータ型とは異なり、複数のタイプのデータ型(数値、文字、倫理など)を含むことができるという点でデータ分析では最も重要なデータ型となります。また、エクセルなどで集めたデータセットに最も近い形であることから、データフレームは、Rで扱う最も一般的なデータ構造です。
データフレームは、「data.frame関数」で作成し、一般形は以下のようになります。
x <- data.frame(col1, col2, col3,...)
- col1, col2, col3, ...は各列に含まれるデータ(数字、文字、論理型など)
例として、冒頭で示した架空のコロナウイル検査結果をデータフレームで作成してみましょう。
| ID | age | vaccine | type | condition |
| 1 | 25 | F | alpha | severe |
| 2 | 34 | T | beta | mild |
| 3 | 28 | T | beta | moderate |
| 4 | 52 | F | alpha | moderate |
| 5 | 71 | T | alpha | critical |
ID <- c(1, 2, 3, 4, 5)
age <- c(25, 34, 28, 52, 71)
vaccine <- c(F, T, T, F, T)
type <- c("alpha", "beta", "beta", "alpha", "alpha")
condition <- c("severe", "mild", "moderate", "moderate", "critical")
pt_data <- data.frame(ID, age, vaccine, type, condition)pt_data
ID age vaccine type condition
1 1 25 FALSE alpha severe
2 2 34 TRUE beta mild
3 3 28 TRUE beta moderate
4 4 52 FALSE alpha moderate
5 5 71 TRUE alpha criticalデータフレームでは、各列内のデータ型は1種類でなければならないですが、異なる列は異なるデータ型で構成することができます。
> typeof(pt_data$ID)
[1] "double"
> typeof(pt_data$age)
[1] "double"
> typeof(pt_data$vaccine)
[1] "logical"
> typeof(pt_data$type)
[1] "character"
> typeof(pt_data$condition)
[1] "character"確認してみると異なるデータ型でデータフレームが構成されていますね。(※上のコードの$マークについては下のデータフレーム内の要素の指定で解説していますので、参照してください)
データフレーム内の要素の指定
データフレームの要素を指定するにはいくつかの方法があります。
- インデックス([ ]:角括弧) を使用
- ドルマーク($) で指定
インデックス([ ]:角括弧)で指定
ベクトルやマトリックスの所で解説した方法と同じで、インデックス([ ]:角括弧)で列名を指定して要素を取り出す事ができます。例えば、サンプルデータから作成したpt_dataのIDとageの要素を取り出す場合は、列番号を指定して、
pt_data[1:2] #1・2列目の要素を取り出す
ID age
1 1 25
2 2 34
3 3 28
4 4 52
5 5 71とすると、IDとageの要素が取り出せます。
また、列番号ではなく、列名を指定することもできます。例えば、pt_dataのtypeとconditionの要素を取り出したい場合は、[ ]とc( )を使って以下のように指定します。
pt_data[c("type", "condition")] #type列とcondition列の要素を取り出す
type condition
1 alpha severe
2 beta mild
3 beta moderate
4 alpha moderate
5 alpha criticalさらに特定の値を取り出すなら、
> pt_data[2,4]
[1] "beta"とすれば、2行目×4列目の要素を取り出すことができます。
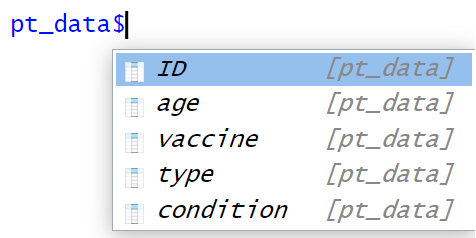
$(ドルマーク)で指定
$マークは任意のデータフレームから特定の列を指定するときに頻繁に使用されます。例えば、pt_dataのageを指定すると、
pt_data$age
[1] 25 34 28 52 71のように、ageのデータを取り出す事ができました。
Rstudioではデータフレーム名+$と入力すると、以下の図のようにデータフレーム内の列名が参照できるのでとても便利ですよ。
他にも、pt_dataからtypeとconditionをクロス集計したい場合なら、以下のような「table関数」を一緒に使うと簡単にクロス集計表を作成することもできますよ。
table(pt_data$type, pt_data$condition) critical mild moderate severe
alpha 1 0 1 1
beta 0 1 1 0データフレーム内でのケース識別子の設定
pt_dataの「ID」はデータセット内の個人を識別するために割り当てられている数字ベクトルです。このケース識別子を「data.frame関数」のrownameオプションで指定することで、Rでグラフ作成するときのラベル付けに使用する変数として設定できます。例えば、
pt_data <- data.frame(ID, age, vaccine, type, condition, row.names=ID)として、IDをケース識別子として設定できます。
ファクター(factor)
データの尺度には、名義尺度、順序尺度、間隔尺度、比例尺度があります。名義や順序尺度変数は質的(カテゴリー)データであり、はっきりとした順序がありません。上記のpt_dataの例を使えば、type (alpha, beta)は、名義尺度の一例です。データ中でalphaが1、betaが2としてコード 化されていても、順序はわかりませんね。また、conditon(mild, moderate, severe, critical)は順序尺度の変数であり、順序(今回の場合は重症度)を意味するが、明確な間隔がありません。つまり、severeはmildやmoderateより「状態が悪い」ことはわかりますが、それぞれの間の差がどの程度かはわかりません。
このような質的(カテゴリー)データに対して、Rでは ファクター(factor)を使います。
ファクター(factor)では、 「factor関数」を使い、カテゴリ値を整数ベクトルに置き換え、これらの整数にマッピングされた元の値を格納します。例えば、
type <- c("alpha", "beta", "beta", "alpha", "alpha")
type <- factor(type)
type
[1] alpha beta beta alpha alpha
Levels: alpha betaとすれば、type内のデータベクトルは 、内部で alpha=1 と beta=2割り当てられて関連付けられています。上の例の場合は「1 2 2 1 1」です。この割当の順序はデフォルトでは、アルファベット順です。
condition <- c("severe", "mild", "moderate", "moderate", "critical")
condition <- factor(condition)
condition
[1] severe mild moderate moderate critical
Levels: critical mild moderate severeとすれば、condition内のデータベクトルは (4 2 3 3 1) として置換して、これらの値を critical=1、mild=2、moderate=3、severe=4と内部的に関連付けます。
もし、アルファベッド順ではデータ解釈に混乱が出る場合、例えば、上のconditionの場合、コンディションが良好なほど小さい整数で表すほうがデータ解釈しやすいですね。このときは、オプションでlevelsを追加します。
condition <- factor(condition, order=TRUE, levels=c("mild", "moderate", "severe", "critical"))
condition
[1] severe mild moderate moderate critical
Levels: mild < moderate < severe < criticalこうすれば、mild=1、moderate=2、severe=3、critical=4、のようにレベルを割り当てます。
リスト(List)
リスト(List)はRのデータ構造中でも最も複雑な構造をしています。あまり難しく考える必要は無いですが、様々な種類のデータを自由に一つのリストに並べてしまうことができるものです。
リスト(List)は、「list関数」を使い、一般的な形は以下のようになります。
x <- list(object1, object2, ...)
試しにリストを作成してみます。
o1 <- "My favorite things"
o2 <- c(1, 2, 3, 4, 5)
o3 <- matrix(1:10, nrow=5)
o4 <- c("TOM", "KEN", "JOE")
x <- list(text=o1, o2, o3, friend=o4)x
$text
[1] "My favorite things"
[[2]]
[1] 1 2 3 4 5
[[3]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
$friend
[1] "TOM" "KEN" "JOE"リスト(List)は各リストに名前を付けることもできます。上の例ではtext、friendはリストに名前をつけています。名前のあるリスト項目には$サイン、名前の無いリストには[[リスト番号]]が付いているのがわかると思います。リストの要素を指定する場合は、この$や[[ ]]を使って指定します。例えば、
x$text
[1] "My favorite things"
x[[2]]
[1] 1 2 3 4 5のようにするとリスト内の要素を指定できます。
まとめ

今回は、Rで扱うデータ型とデータ構造について初心者の方でも理解出来るように例を挙げながら解説しました。Rのデータ型とデータ構造は一度しっかりと理解しておけば、Rでの分析の際に混乱せず、スムーズにデータ分析ができますよ。


コメント