
以前にエクセルの基本統計量のような記述統計結果をRで簡単に求める方法を紹介しました。
今回はその復習にプラスして他の方法を紹介します。多くはパッケージを使ったものですから簡単に、詳しい記述統計量を求めることができますので、是非、試してみてください。
今回は、連続変数の中心傾向、ばらつき、分布ついての記述統計量を求めていきます。
サンプルデータ作成
サンプルデータとしてMASSパッケージのCars93からいくつかのデータを使用します。
まず、サンプルデータとして、Cars93データの燃費、馬力、重量を選びます。
library(MASS)
mydata <- c("MPG.city", "Horsepower", "Weight")
head(Cars93[mydata])
すると、データは以下のようになります(上位6データのみ表示)。
head(Cars93[mydata])
MPG.city Horsepower Weight
1 25 140 2705
2 18 200 3560
3 20 172 3375
4 19 172 3405
5 22 208 3640
6 22 110 2880
summary()関数
まずは、復習も兼ねて、summary()関数です。
summary(Cars93[mydata])
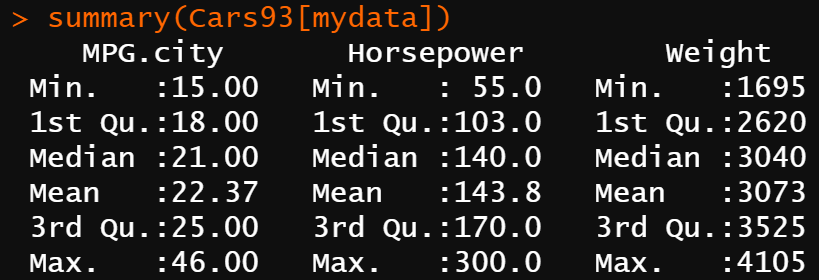
summary() 関数では、
- 最小値
- 第1四分位数
- 中央値
- 平均値(数値ベクトルの場合)、度数(factorや倫理ベクトル場合)
- 第3四分位数
- 最大値
を求めることができますね。
describe():psychパッケージ
psychパッケージのdescribe()関数を使えば、
- 変数番号 (vars)
- データ数 (n)
- 平均値 (mean)
- 標準偏差 (sd)
- 中央値 (median)
- 10%トリム平均 (trimmed):デフォルトは10%設定となっている
- 中央絶対偏差 (mad): median absolute deviationの略で、中央値からのバラつき度合いを表す
- 最小 (min)
- 最大 (max)
- 範囲 (range)
- 歪度 (skew)
- 尖度 (kurtosis)
- 標準誤差 (se)
を求めることができます。
library(psych)
describe(Cars93[mydata])

ワンポイント:psychパッケージと今回は紹介していないHmiscパッケージの両方にdescribe() 関数があります。少し紛らわしいのでHmiscのdescribe()の説明は省略していますが、こちらも詳細な記述統計量を表してくれます。では、Rはどのようにして、describe()がどちらのパッケージに属したものかを判断するのでしょうか?
答えはとてもシンプルです。
Rは最後に読み込まれたパッケージを優先させます。つまり両方のパッケージをLoadしていても、psychパッケージの後にHmiscパッケージをロードすれば、Hmiscのdescribe()関数を優先して実行します。
stat.desc():pastecsパッケージ
前回も紹介しましたが、pastecsパッケージにはstat.desc()という関数があり、こちらも様々な記述統計量を求めることができます。
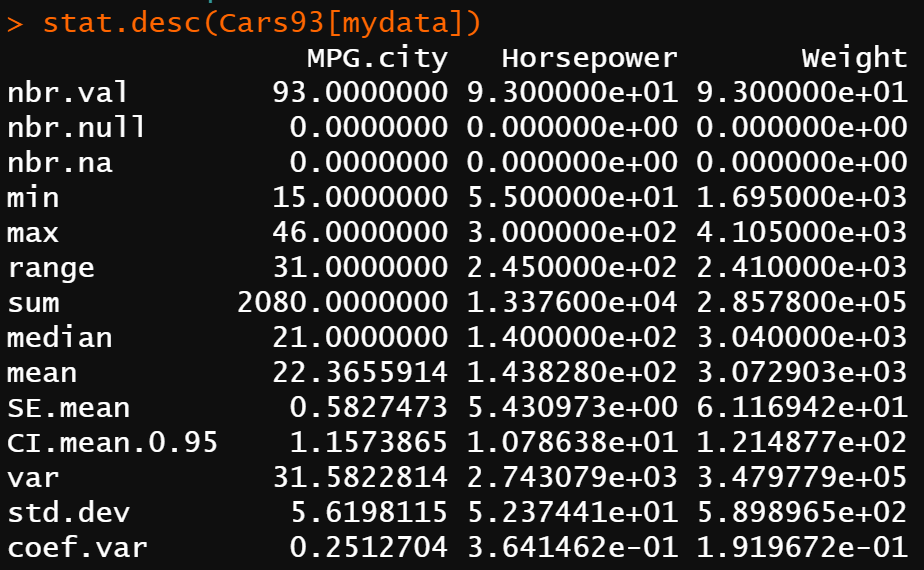
- 値の数(nbr.val)
- NULL値の数(nbr.null)
- 欠損値の数(nbr.na)
- 最小値(min)
- 最大値(max)
- 範囲(範囲、つまり max-min)
- (欠損していないすべての値の)合計(sum)
- 中央値 (median)
- 平均値 (mean)
- 平均値の標準誤差 (SE.mean)
- 平均値の95%信頼区間 (CI.mean)
- 分散 (var)
- 標準偏差 (std.dev)
- 変動係数 (coef.var)
library(pastecs)
stat.desc(Cars93[mydata])
aggregate()関数を使った分類別の基本統計量
グループごとの(分類別)に記述統計量を比較したときもありますね。つまり個人個人やグループを比較するときは標本全体ではなく、各グループの記述統計量が必要になってきます。
これはaggregate()関数を使います。
以前にaggregate()関数を使ったmean bar plotを作成する方法を説明しましたね。
同様にaggregate()関数を使って、各グループごとの記述統計量を得ることができます。
まず、aggregate()関数の基本形は以下の通りです。
aggregate(x, by, FUN)
- x: 集計する列
- by: カテゴリー別に集計する列を指定。この時、by = list()とする
- FUN: 関数
例えば、これまで使ったmydataをOrigin(アメリカのデータなので、アメリカ製:USE or 海外製:non-USA)で分類した比較をしてみます。
aggregate(Cars93[mydata], by = list(Origin = Cars93$Origin), mean)

データを分類する方法は、by =list(Origin = Cars93$Origin)としています。
複数の変数の場合、
by=list(name1=groupvar1, name2=groupvar2, ... , groupvarN)
のようなコードを使用することができます。一方で、aggregate() では、単一関数しか使用できないので、一度に複数の統計量を求めることはできません(※上の例では平均値のみ)。
describeBy()関数:psychパッケージを使った分類別の基本統計量
psychパッケージのdescribeBy()関数を使えば、グループ別の基本統計量を簡単に求めることができます。
library(psych)
describeBy(Cars93[mydata], Cars93$Origin)
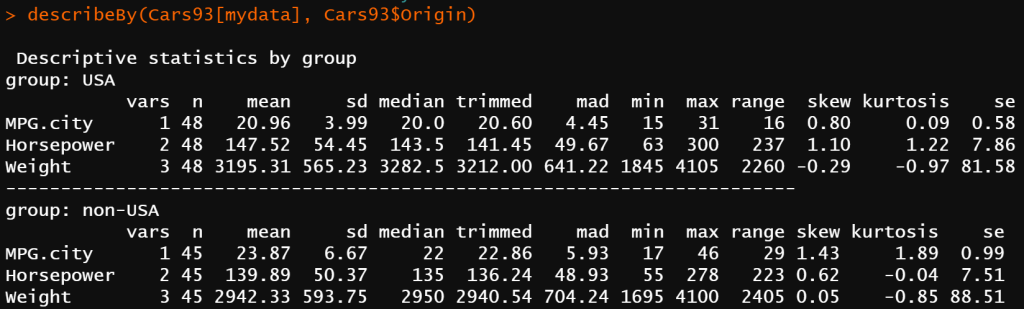
上記の結果のように、USAとnon-USAで分類された記述統計量を求めることができました。
まとめ

今回は、「Rを使った記述統計を簡単に!」をテーマに集めたデータから簡単に基本統計量を求める方法を紹介しました。パッケージを使用したもがほとんどですからとても簡単に実践できると思いますので、是非、試してみてください。


コメント