エクセルのアドインには「分析ツール」というのがあるのはみなさんご存じですか?
これを使うと、エクセルに入力したデータの「平均・標準誤差・中央値・最頻値・標準偏差・分散・尖度・歪度・範囲・最小・最大・合計・データの個数」が一瞬で出てくるという優れものの機能です。
しかし、Rも負けてはいませんよ。
エクセルの基本統計量に負けない基本統計量を求める関数が備わっています(※備わっていなくてもパッケージを導入することで可能になります)。
そこで、今回はRを使って基本統計量を求める方法としてsummaryとstat.descを解説しますね
summary関数
最も簡単な基本統計量を求める関数はsummary関数です。
summary関数はデータフレームの各項目(列)毎に、
- Min.:最小値
- 1st Qu.:第1四分位数
- Median:中央値
- Mean:平均値
- 3rd Qu.:第3四分位数
- Max.:最大値
の基本統計量を計算してくれます。
また、データがカテゴリーデータの場合は、カテゴリーの合計を計算してくれます。
例として、MASSパーケージ内にあるanorexia(拒食症)データを使ってsummary関数を実行してみます。
ちなみに、anorexiaデータは72人の拒食症患者に対して、認知行動療法(CBT)・家族療法(FT)・コントロール(Cont)のいずれかを行った治療前・治療後の体重(lb = ポンド、1ポンド=453g)データです。
項目はTreat(カテゴリーデータ)とPrewt・Postwt(数的データ)が含まれています。
library(MASS)
summary(anorexia)
と入力すると、
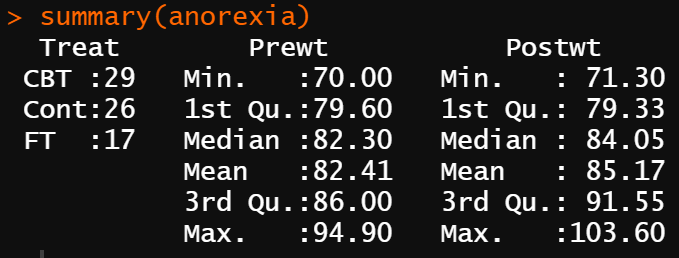
となり、カテゴリーデータであるTreatは各介入法の合計、数的データであるPrewtとPostwtは基本統計量が求められます。
stat.desc関数
さらに多くの基本統計量を表示する関数として、pastecsパッケージのstat.desc関数があります。
このstat.desc関数を使えば、
- nbr.val:データの個数
- nbr.null:NULLデータの個数
- nbr.na:欠損データの個数
- min:最小値
- max:最大値
- range:範囲
- sum:合計(欠損値を除いた)
- median:中央値
- mean:平均値
- SE.mean:標準誤差
- CI.mean:信頼区間
- var:分散
- std.dev:標準偏差
- coef.var:変動係数
を求めることができます。
先程のanorexiaデータを再度、使ってstat.desc関数を実行してみます。
既にpastecsパッケージをインストールしている方は、1行目は飛ばしてください。
install.packages("pastecs")
library(pastecs)
stat.desc(anorexia)
で、結果は以下のようになります。
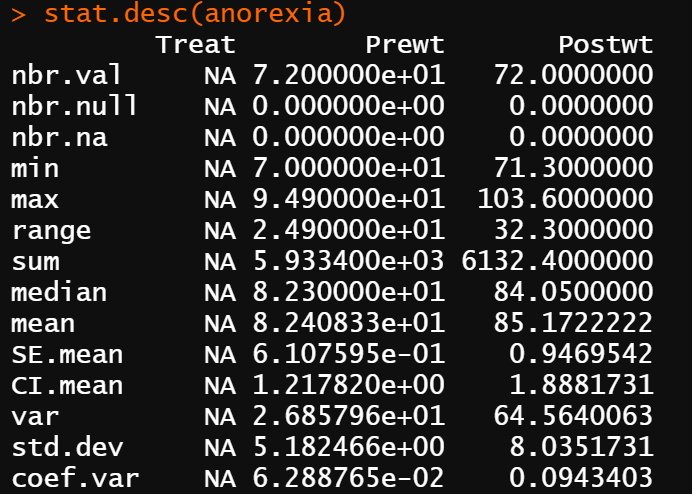
項目のTreatはカテゴリーデータなので、すべてNAとなっていますね。
まとめ
以上で、Rを使った基本統計量の求め方を解説しました。
どちらの関数もとても簡単で、便利でしょう!


コメント