単回帰分析とは
単回帰分析は、2つの変数間の関係を要約して調べることができる統計手法です。このとき、
- x軸:予測変数・説明変数・独立変数
- y軸:応答変数・結果変数・従属変数
と呼ばれます。
今回の説明では、xを「予測変数」、yを「応答変数」とします。
単回帰分析では、1つの予測変数のみのを扱うので、「単」という形容詞がつきます。一方、2つ以上の予測変数が関わる場合は「重」がついて、重回帰分析と呼ばれます。(※重回帰分析についてはまた別の機会に説明します。)
例えば、以下のような体重と身長データセットある時、xを体重、yを身長として散布図を書くと以下のようになります。
| weight(㎏) | height(㎝) |
| 64 | 160 |
| 62 | 164 |
| 59 | 160.5 |
| 60 | 158 |
| 41 | 148 |
| 48 | 157 |
| 50 | 151.8 |
| 53.5 | 151.2 |
| 36 | 144.8 |
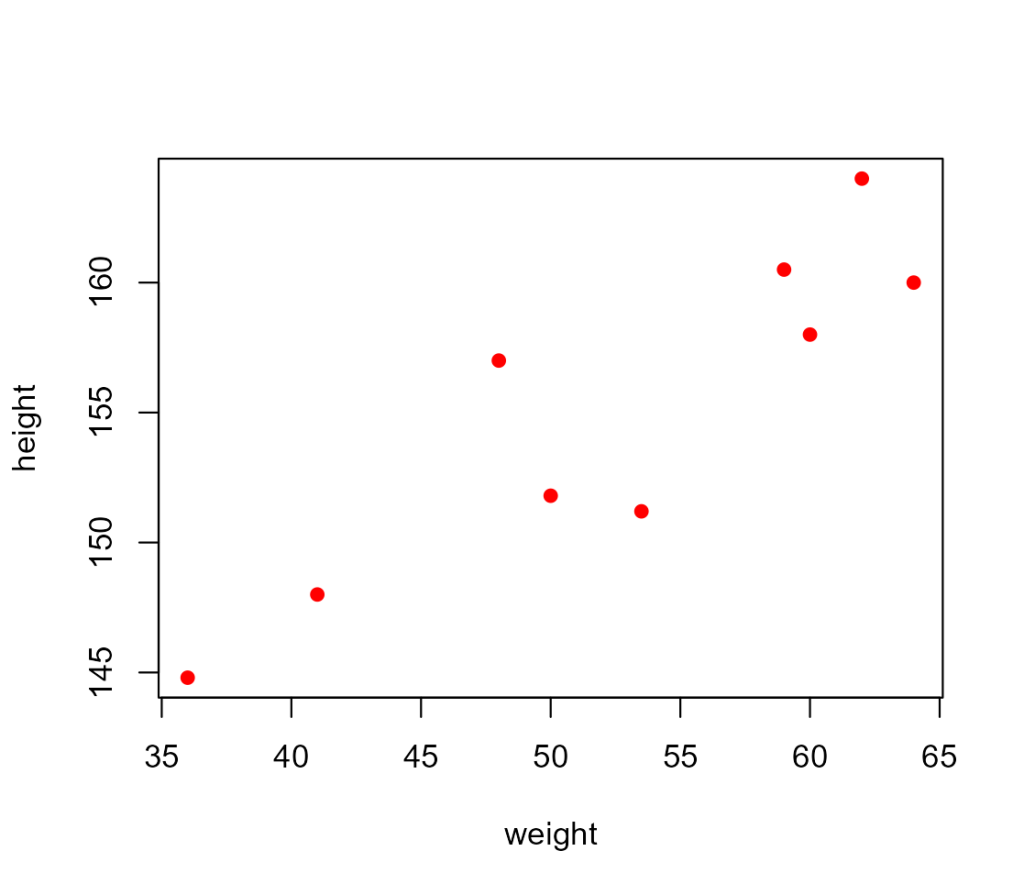
この散布図から、体重が増加すると身長も増加する傾向があることが予測できますが、この傾向を実際に数値化したのが、単回帰直線です。
単回帰直線の公式
単回帰分析を使うことで散布図上の全データに最も「フィット」する直線を見つけることができます。さらに、この直線から体重と身長の関係を理解することが可能となります。
回帰直線の一般式
$$ý = a + bx$$
$$b =\frac{\sum(x - \bar{x})(y-\bar{y})}{\sum(x -\bar{x})^2}$$
$$a = \bar{y} - b\bar{x}$$
Rによる単回帰分析
上の公式を使っても単回帰直線を求めることは可能ですが、やはりRを使えば単回帰直線以外も分析も一発に解析できるのでお勧めします。
では、lm()関数を使って回帰直線を求めてみます。
まず、上の例をデータフレームの形にします。
weight <- c(64.0,62.0,59.0,60.0,41.0,48.0,50.0,53.5,36.0)
height <- c(160.0,164.0,160.5,158.0,148.0,157.0,151.8,151.2,144.8)
w_h <- data.frame(weight, height)
これで、上の例のデータフレームができました。では、lm()関数の出番です。
lm(応答変数~予測変数, data = データフレーム名)が一般的な形式です。
そして、summary()関数で詳細を表示させます。
w_h.reg <- lm(height ~ weight, data = w_h)
summary(w_h.reg)
すると、結果は以下のようになります。
Call:
lm(formula = height ~ weight, data = w_h)
Residuals:
Min 1Q Median 3Q Max
-4.3590 -1.6893 -0.4104 1.6886 4.6934
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 123.9220 5.8701 21.111 1.35e-07 ***
weight 0.5913 0.1099 5.379 0.00103 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.016 on 7 degrees of freedom
Multiple R-squared: 0.8052, Adjusted R-squared: 0.7774
F-statistic: 28.94 on 1 and 7 DF, p-value: 0.001031
Estimate(黄色の文字)の
- (intercept):切片、つまり "a"
- weight:傾き、つまり "b"
結果、上の例の回帰直線は
ý = 123.9 + 0.59x
となります。
回帰直線の見方
この回帰直線:ý = 123.9 + 0.59x は、
体重が1㎏増加すると、身長は0.59㎝増加することを意味します。
ちなみに、体重が0㎏の時に予測される身長が123.9㎝ですが、人の体重が0㎏になることはありえないので、
b=0を解釈することは実際には意味を持ちません。
回帰直線で予測
さらに、回帰直線を使って予測することができます。
例えば、先程求めた回帰直線から、体重が 60㎏なら、身長は何センチになるが予想できます。
ý = 123.9 + 0.59×60 = 159.3
Rを使って予測することも可能です。予測にはpredict()関数を使います。
predict(線形モデル名、data.frame(項目名=c(値,...)))が一般的な形式です。
項目名=c()の中には複数の値を入れて、複数の値を一度に予測することも可能です。
predict(w_h.reg,data.frame(weight=c(60)))
とすると、159.4027という結果が表されますので、実際に試してみてください。
注意:
- 回帰式を使って予測を行うときは、回帰式を算出するために使用した元データの範囲内にある予測変数だけを使用してください。
- 例えば、上の例なら、体重は36~64㎏の範囲ですので、体重が36~64㎏の間で身長に関する予測であれば大丈夫です。
決定係数
回帰直線がどれだけデータに「フィット」しているかを見極める指標として、決定係数(R2)があります。
上の例のsummary(w_h.reg)の結果の下から2行目(黄色の文字)の
Multiple R-squared: 0.8052
が決定係数です。
決定係数は、0 ~ 1 の範囲をとり、
決定係数が0ならば、応答変数が予測変数によって全く説明されないことを示し、
1ならば、応答変数が予測変数によって完全に説明されることを示します。
そして、0 と~1 の間の R2 は、応答変数が予測変数によってどれだけよく説明されるかを示します。
例えば、上の例では、R2が0.8052ですので、身長の80.52%が体重で説明できることを示しています。
このことから、体重は身長の予測因子として非常に優れていることがわかりますね。
まとめ

単回帰分析について、できるだけ簡単にまとめてみました。Rを使えば直ぐに単回帰分析を求めることができます。データの関係を分析する際には散布図と一緒に行えばとても便利な統計ツールですよ。


コメント